مانیتورینگ ELK چیست
مقدمه
مانیتورینگ یک رویکرد فعالانه برای ایمن سازی محیط است که پاسخ دهی مناسب را برای بررسی آن محیط به صورت real time فراهم میکند. برای این منظور ابزار های زیادی وجود دارد که میتوان با استفاده از آن به خواسته های خود رسید.
در مورد ما صحبت در مورد openstack می باشد که ما نیاز به مانیتور کردن سخت افزار، سرویس ها و منابع ابری خود داریم (منابع ابری شامل تمام ویژگی هایی است که در openstack ساخته میشود مانند instance, network و …)
برای پیاده سازی یک log aggregation ، تحلیل و مانیتورنیگ آن نیاز است که به چند مورد مهم توجه کنیم. برای مانیتورینگ می توانیم از ابزار های متفاوتی که برای این منظور ایجاد شده اند استفاده کنیم. برخی از این ابزار ها opensource بوده و برخی نیز توسط شرکت های دیگر پشتیبانی می شود. برخی روش ها هم می تواند کاملا شخصی سازی شده باشد. این ابزار ها رویداد ها را ثبت کرده و می تواند کاربر اصلی سیستم را از ان رویداد مطلع سازد. برای ایجاد این سیستم ها باید چند نکته را مورد توجه قرار دهید.
- شناسایی عدم وجود سیستم لاگ خود یک رویداد با اولیت بالا می باشد. چنین رویدادی نشانه خرابی سیستم است یا ممکن است نشانه ورود یک متجاوز به سیستم باشد که سرویس را به طور موقع غیر فعال کرده است تا حرکت های خود را مخفی کند.
- رویداد هایی مانند خاموش یا روشن شدن یک سرویس که در برنامه زمان بندی جاری وجود ندارد ممکن است یک دلیل امنیتی باشد.
- رویداد های سیستم عامل مانند ورد و خروج کاربران یا راه اندازی مجدد سیستم دید مناسبی از نوع کاربری از سیستم را نشان میدهد.
- شناسایی بار زیاد سرور های موجود می تواند توصیف خوبی از شرایط برای ایجاد یک تقسیم کننده بار یا افزودن سرور جدید جهت دسترسی بالا را فراهم کند.
- قطع شدن bridge ها می تواند عدم دسترسی به سرویس توسط مشتری را ایجاد کند در نتیجه بررسی وضعیت آن ها لازم خواهد بود.
- برای کاهش ریسک حذف یک ماشین توسط کاربر یا پروژه یا دامنه در سرویس احراز هویت باید در سرویس های دیگر وابستگی ها به این موجودیت بررسی گردد.
در ابر ماشین های مجازی زیادی ممکن است وجود داشته باشد و مانیتور کردن این ماشینها فراتر از مانیتور سخت افزار و فایل های لاگ است که فقط ارتباط با دیتابیس را شامل میشود.
Openstack و journal
در سرویس openstack سرویس جمع آوری کننده لاگ ها از syslog به journal مهاجرت نموده است. در گذشته برای جمع آوری لاگ ها در محیط openstack از rsyslog استفاده میشد. (نسخه stein به قبل) در playbook های انزیبل راه اندازی و جمع آوری لاگ های تمام سرور ها و سرویس های آن در یک کانتینر پیاده سازی شده است.
infra-journal-remote.yml به صورت پیشفرض غیر فعال می باشد و در هنگام نصب باید اعلام شود که نیاز به نصب دارد. پس از نصب تمام سرویس هایی که در سرور قرار دارند و لاگ آن ها در journal ذخیره شده است به سرور مرکزی که openstack-user-config.yaml معرفی شده منتقل میگردد.
این انتقال توسط سرویس systemd-journal-upload.service انجام میشود و مسئولیت جمع آوری آن بر عهده سرویس systemd-journal-remote.service می باشد که باید در سرور مقصد فعال گردد.
پس از اجرای playbook نصب لاگ منجیر این سرویس ها به صورت اتومات بر روی سرور های infra و compute نصب خواهد شد و می توانیم مانیتورینگ یک پارچه این سرورها را در مبحث لاگ داشته باشیم. توجه داشته باشید که حجم لاگ های ارسالی زیاد خواهد بود و باید جهت مدیریت آن کافنیگ های مورد نیاز خورد را اعمال نمایید. در ادامه به بحث کانفیگ های جورنال و افزودن سرویس های کانتینر به آن می پردازیم.
برای مطالعه بیشتر در مورد مانیتورینگ شبکه با elk میتواند به این مقاله مراجعه کنید
دوره مدیریت لاگ با elk میتواند برای درک بهتر بسیار مفید باشد – دوره مدیریت لاگ با ELK
فصل دوم سرویس های مانیتورینگ ELK
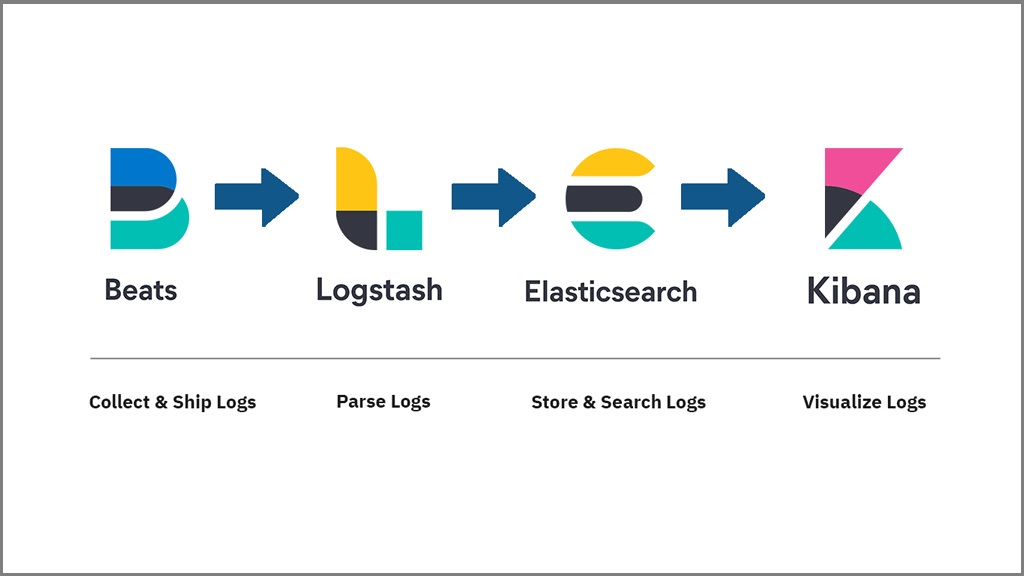
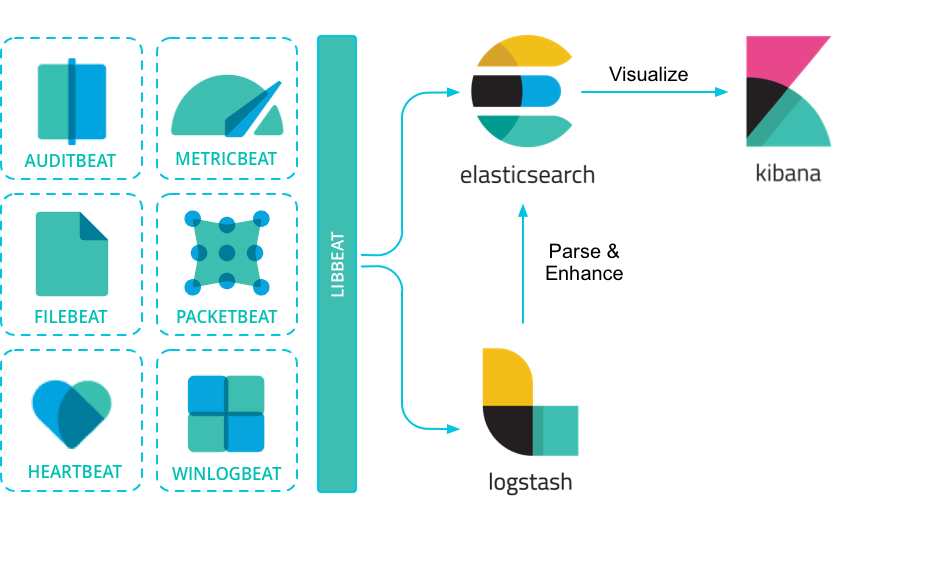
Beats
در بیشتر سرویس های مانیتورینگ مسئولیت جمع آوری اطلاعات بر عهده یک سرویس در سرور مرکزی خواهد بود. در ELK پرکاربردترین ابزار beats است. این ابزار شامل چندین سرویس مختلف برای جمع آوری انواع داده می باشد. برای مثال filebeat که اطلاعات را از یک فایل خوانده و آن ها را جمع آوری میکند و برای مقصد دلخواه ارسال می نماید. یا metricbeat که اطلاعات مربوط به سیستم سخت افزاری سرور مانند پردازش گر یا هارد دیسک را جمع آوری کرده و ارسال می کند. در این مقاله ما از journalbeat که جهت جمع آوری لاگ ها از journal می باشد را استفاده میکنیم و آن را به سرور مقصد ارسال میکنیم. در فصل های بعد تنظیمات و روش نصب این سرویس را نشان خواهیم داد.
Elasticsearch
اطلاعات جمع آوری شده برای مانیتورینگ می توانند به صورت آنی فقط برای نمایش لحظه ای مورد استفاده قرار بگیرند. اما در بیشتر مواقع شما نیاز خواهید داشت که اطلاعات جمع آوری شده را برای مدت طولانی نگهداری کنید و بتوانید در هر زمان با سریع ترین روش به آن ها دسترسی پیدا کنید. یکی از روش های ذخیره سازی استفاده از ابزاری با نام elasticsearch خواهد بود که اطلاعات را دریافت، ایندکس و ذخیره سازی می کند و با ارائه فیلتر های مناسب امکان query های مورد نظر شما را فراهم میکند.
این ابزار قابلیت scale شدن به صورت افقی را داشته و می توان از آن در محیط های با پردازش سنگین داده که قابلیت تخصیص منابع یکپارچه در سیستم را ندارند استفاده نمود. به طور کلی قلب elk این ابزار می باشد.
از قابلیت های این ابزار دریافت اطلاعات به صورت داده های خطی یا raw دیتا می باشد که پس از پردازش و تحلیل این خطوط داده آنها را normalize کرده و آن ها را ذخیره سازی میکند. امکانات این ابزار بیشتر در زمان نمایش داده ها نشان داده خواهد شد.
Elasticsearch هسته اصلی در Elk می باشد. تمام فرایند های ذخیره سازی و ایندکسینگ در این ابزار انجام میپذیرد. نوع ذخیره سازی document-oriented می باشد و ساختار ذخیره سازی به صورت JSON خواهد بود. برای کار با این ابزار نیاز به دانستن مفاهیم زیر می باشد.
- Index
- Type
- Document
- Cluster
- Node
- Shards and replica
- Mapping and type
- Inverted index
بیایید مفاهیم اصلی را با یک مثال پیش ببریم.
PUT /catalog/product/1
{
"sku":"SP000001",
"title":"Elasticsearch for Hadoop",
"description":"Elasticsearch for Hadoop",
"author":"Vishal Shukla",
"ISBN":"1785288997",
"price": 26.99
}این این مثال PUT /catalog/product/1 یک درخواست put است که در ادامه آن یک document از نوع json وجود دارد. در اینجا catalog نام index می باشد و product نام یک type خواهد بود که در آن داکیومنت ما ایندکس می شود. عدد یک id است که پس از index شدن داکیومنت به آن اضافه خواهد شد. حال به توصیف هر کدام از مفاهیم می پردازیم.
ایندکس ظرفی است که داکیومنت ها از یک نوع را ذخیره و مدیریت می کند. ایندکس ها می توانند شامل داکیومنت هایی از یک نوع باشند که در تصویر زیر قابل مشاهده است.
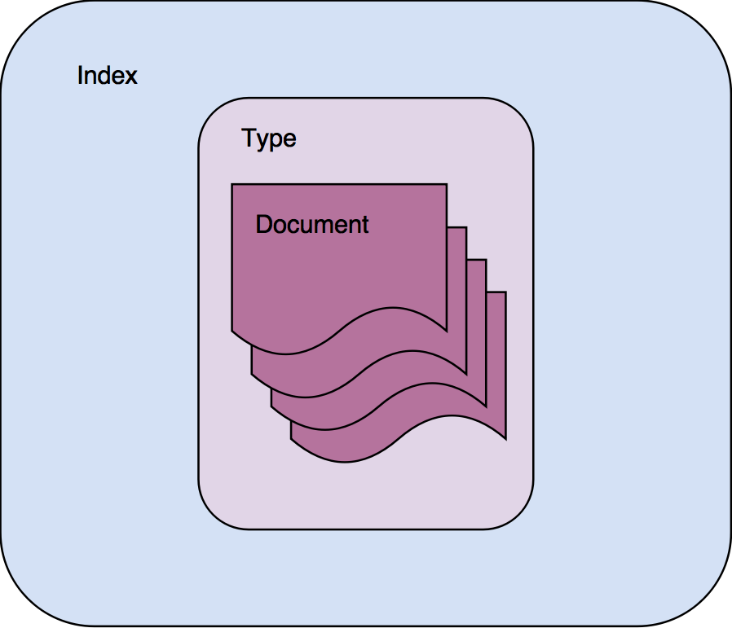
این طبقه بندی یک طبقه بندی منطقی است برخی از پارامتر های تنظیمات در index ذخیره می شود و برخی دیگر در بخش type تعریف میگردند. تعریف index مشابه تعریف schema در دیتابیس های رابطه ای می باشد. type نیز مشابه تعریف جدول در دیتابیس های رابطه ای می باشد. و داکیومنت نشان دهنده یک سطر خواهد بود.
بررسی معماری Hot , warm و cold
مدیریت شاخص چرخه عمر(ILM) یک ویژگی است که برای اولین بار درElasticsearch 6.6بتا موجود در6.7معرفی شد است. ILMبخشی ازElasticsearchاست و برای کمک به شما در مدیریت شاخص های شما طراحی شده است.
در این پست وبلاگ به شما نشان خواهیم داد که چگونه می توانید یک معماریwarmوcoldوhotرا باILMپیاده سازی کنید.معماریwarmوcoldوhotبرای داده های سری زمانی معمول است مانند ورود به سیستم یا داده های متریک.به عنوان مثال ، فرض کنید ازElasticsearchبرای جمع آوری پرونده های ورود به سیستم از سیستم های مختلف استفاده می شود.گزارش های امروز فعالانه نمایه می شوند و گزارش های هفته جاری بیشترین جستجو را دارند(hot).گزارش های مربوط به هفته قبل جستجو می شود ، اما به دفعات گزارش های هفته جاری(warm)نیست.گزارش های مربوط به ماه گذشته اغلب جستجو نمی شوند ، اما در موارد جداگانه(cold)می توانند بسیار مفید باشند.
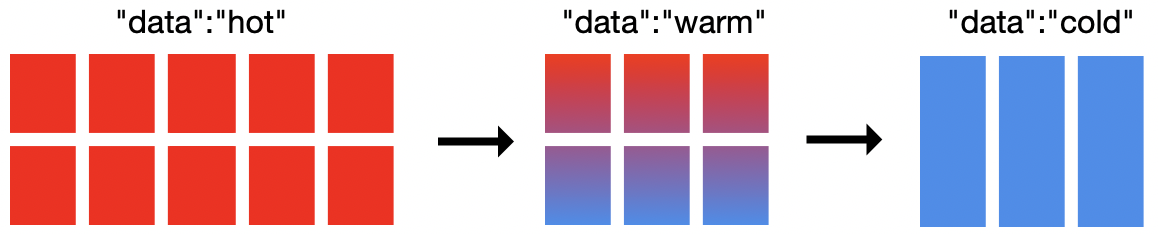
خوشه در شکل بالا شامل19گره است: 10گره داغ ،6گره گرم و3گره سرد.برای اجرای گرم و گرم و سرد باILMلزوماً به19گره نیاز ندارید ، اما حداقل به2گره نیاز دارید.بازتاب به اندازه نیازهای خوشه خود رادر مورد نیاز شما بستگی دارد.گره های سرد اختیاری هستند و فقط یک سطح اضافی را در مدل ارائه می دهند که می توانید داده های خود را در آن ذخیره کنید.باElasticsearchمی توانید گره های داغ ، گرم یا سرد را تعیین کنید.باILMمی توانید تعیین کنید چه زمانی انتقال فاز اتفاق می افتد و چه اتفاقی برای شاخصی می افتد که به یک مرحله خاص می رسد.
هیچ طرحی آماده برای معماری سرد و گرم وجود ندارد.با این حال ، به طور معمول ، شما باید اطمینان حاصل کنید که گره های گرم شما از پردازنده بیشتری برخوردار می شوند و ورودی و خروجی آنها سریعتر است.گره های گرم و سرد اغلب به فضای دیسک بیشتری در هر گره نیاز دارند ، اما باCPUوI / Oکمتری عبور می کنند.
خوب بیایید شروع کنیم…
Hot-warm-coldبر اساسshard Allocation Awarnessاست.بنابراین ، ما ابتدا گره های داغ ، گرم و سرد(اختیاری)خود را مشخص می کنیم.برای این کار ، ما یا پارامترهای شروع خود را ویرایش می کنیم یا فایل پیکربندیelasticsearch.yml.مثلا:
bin/elasticsearch -Enode.attr.data=hot
bin/elasticsearch -Enode.attr.data=warm
bin/elasticsearch -Enode.attr.data=coldبرای مطالعه بیشتر در مورد مانیتورینگ شبکه با elk میتواند به این مقاله مراجعه کنید
پیکربندی خط مشیILM
بعد ما یک خط مشیILMرا پیکربندی می کنیم.از دستورالعمل هایILMمی توان در هر تعداد شاخص استفاده مجدد کرد.سیاست هایILMبه چهار مرحله داغ ، گرم ، سرد و خاموش شدن تقسیم می شوند.در هر خط مشی نیازی به تعریف هر مرحله نیست ، وILMهمیشه مراحل را به ترتیب ترتیب انجام می دهد و از مراحل نامشخص رد می شود.برای هر مرحله ، شما باید تعیین کنید که مرحله شروع می شود و چه اقداماتی در شاخص های خود انجام دهید.برای معماری های داغ و گرم ، می توانید عملکردAllocateرا برای انتقال داده های خود از گره های داغ به گرم و از گرما به سرد پیکربندی کنید.
علاوه بر انتقال داده ها بین گره های داغ ، گرم و سرد ، می توانید بسیاری از اقدامات دیگرراپیکربندی کنید.ازعملrollover برای مدیریت اندازه یا سن هر شاخص استفاده می شود.برای بهینه سازی نمایه های خود می توانید از اقدامForce Merge استفاده کنید.برای کاهش استفاده از حافظه در خوشه می توانید از عملکردFreeze استفاده کنید.برای کسب اطلاعات بیشتر در مورد بسیاری از اقدامات موجود برای نسخهElasticsearchخود ، بهاسنادمراجعه کنید.
خط مشی ساده ILM
این یک دستورالعمل بسیار ساده ILM است:
PUT /_ilm/policy/my_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_size":"50gb",
"max_age":"30d"
}
}
}
}
}
}این خط مشی مشخص می کند که بعد از 30 روز یا هنگامی که اندازه شاخص به 50 گیگابایت رسید (بر اساس خرده ریزهای اولیه) ، یک تغییر شکل انجام می شود و سپس داده ها در یک فهرست جدید نوشته می شوند.
الگوهایILMوindex
سپس باید راهنمایILMرا به یک الگوی فهرست رسم کنیم:
PUT _template/my_template
{
"index_patterns": ["test-*"],
"settings": {
"index.lifecycle.name":"my_policy",
"index.lifecycle.rollover_alias":"test-alias"
}
}توجه: هنگام تعیین اقدام چرخش ، باید خط مشی ILM را در الگوی فهرست (و نه مستقیماً در فهرست) مشخص کنید.
اگر خط مشی ای شامل عمل چرخش باشد ، باید پس از ایجاد الگوی فهرست ، فهرست را با نام مستعار نوشتن راه اندازی کنید.
PUT test-000001
{
"aliases": {
"test-alias":{
"is_write_index": true
}
}
}اگر تمام پیش شرط های بازیابی وجود داشته باشد ، تمام نمایه های جدیدی که با “test- *” شروع می شوند پس از 30 روز یا 50 گیگابایت به طور خودکار بازگردانی می شوند. اگر تغییر شاخص را برای شاخص های خود مطابق با “max_size” پیکربندی کنید ، می توانید تعداد خرده ریزها (و در نتیجه کار اضافی) شاخص های خود را به میزان قابل توجهی کاهش دهید.
پیکربندی خط مشیILMبرایingest
BeatsوLogstashازILMپشتیبانی می کنند و خط مشی پیش فرض مشابه نمونه نشان داده شده در بالا تنظیم می کنند. BeatsوLogstashهمچنین کلیه نیازهای مربوط بهعملrolloverراپردازش می کنند .اگرILMبرایBeatsوLogstashفعال باشد و شاخص های روزانه خیلی بزرگی(> 50گیگابایت در روز)نداشته باشید ، اندازه احتمالاً مهمترین عامل در ایجاد شاخص های جدید است.این نشانه خوبی است! ILM with rolloverبه عنوان پیش فرضBeatsوLogstashاز7.0.0استفاده می شود.
با این حال ، از آنجا که هیچ راه حل استانداردی برای معماری داغ و گرم-سرد وجود ندارد ،BeatsوLogstashبا دستورالعمل های داغ-گرم-سرد ارسال نمی شوند.ما می توانیم سیاست جدیدی را ایجاد کنیم که از دلغ و سرد-گرم پشتیبانی کند و در کنار هم تغییراتی ایجاد کنیم.
ما می توانیم سیاست پیش فرض را برایBeatsیاLogstashتنظیم کنیم.با این حال ، این امر خط تقسیم بین رفتار از پیش تنظیم شده و رفتار سفارشی را محو می کند.همچنین ، اگر سیاست پیش فرض را تغییر دهیم ، خطر این را داریم که در نسخه های بعدی سیاست صحیح اعمال نشود(الگوهای پیش فرضBeatsبا نسخه های7.0+تغییر می کنند) .ما می توانیم از پیکربندیBeatsوLogstashبرای تعیین رهنمودهای خود در مورد هر پیکربندی استفاده کنیم.این رویکرد کارساز است ، اما ممکن است شما نخواهید که تنظیمات صدها(یا هزاران)ضربان را برای مطابقت با خط مشیILMتغییر دهید.رویکرد سوم ازتطبیق چند الگواستفاده می کندبرای کنترل کامل سیاستILMبهElasticsearch.
بهینه سازیILM برایhot ،warm وcold
ما ابتدا یک دستورالعملILMایجاد خواهیم کرد که برای معماریwarmوcoldوhotبهینه شده است.باز هم ، هیچ راه حلی متناسب با همه وجود ندارد و احتمالاً نیازهای متفاوتی خواهید داشت.
PUT _ilm/policy/hot-warm-cold-delete-60days
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size":"50gb",
"max_age":"30d"
},
"set_priority": {
"priority": 50
}
}
},
"warm": {
"min_age":"7d",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"shrink": {
"number_of_shards": 1
},
"allocate": {
"require": {
"data":"warm"
}
},
"set_priority": {
"priority": 25
}
}
},
"cold": {
"min_age":"30d",
"actions": {
"set_priority": {
"priority": 0
},
"freeze": {},
"allocate": {
"require": {
"data":"cold"
}
}
}
},
"delete": {
"min_age":"60d",
"actions": {
"delete": {}
}
}
}
}
}فاز های مختلف داده در کلاستر
داغ
این سیاستILMاولویت شاخص را بالا قرار می دهد تا شاخص های داغ قبل از شاخص های دیگر دوباره ساخته شوند.بعد از30روز یا50گیگابایت ، هر کدام که اول شود ، این شاخص رول می شود و یک شاخص جدید ایجاد می شود.با استفاده از شاخص جدید ، خط مشی مجدداً شروع می شود و شاخص فعلی(که تازه روی آن غلتیده شده است)تا هفت روز پس از غلظت به مرحله گرم منتظر می ماند.
گرم
اگر شاخص در فاز گرم است،ILMکاهش شاخص به تکه های شکسته، انجام ادغام نیروی شاخص در یک بخش، مجموعه اولویت اول را به یک مقدار پایین تر از داغ(اما بالاتر از گرم)و با استفاده از تخصیص عمل ، برای انتقال شاخص به گره های گرم در آنجا شاخص30روز منتظر می ماند(از زمان شروع به کار)تا زمانی که وارد مرحله سرد شود.
سرد
به محض ورود شاخص به مرحله سرد ،ILMاولویت شاخص را بار دیگر کاهش می دهد تا اطمینان حاصل شود که ابتدا شاخص های گرم و گرم بازیابی می شوند.سپس این شاخص یخ زده و به گره یا گره های سرد منتقل می شود.در آنجا شاخص60روز منتظر می ماند(از زمان شروع به کار)تا زمانی که وارد مرحله حذف شود.
پاک کردن
ما هنوز مرحله حذف را بررسی نکرده ایم.به طور خلاصه…در مرحله حذف ، اقدام به حذف شاخص انجام می شود.شما همیشه باید”min_age”را برای مرحله حذف تعیین کنید تا شاخص شما در مدت زمان دلخواه در فاز گرم ، گرم یا سرد باقی بماند.
ایجاد سیاستILM در کیبانا
از نوشتن کدJSONخسته شده اید؟(این رویکرد توسط کیبانا نیز قایل پیاده سازی است)بیایید خط مشی را در رابط کاربریKibanaایجاد کنیم:
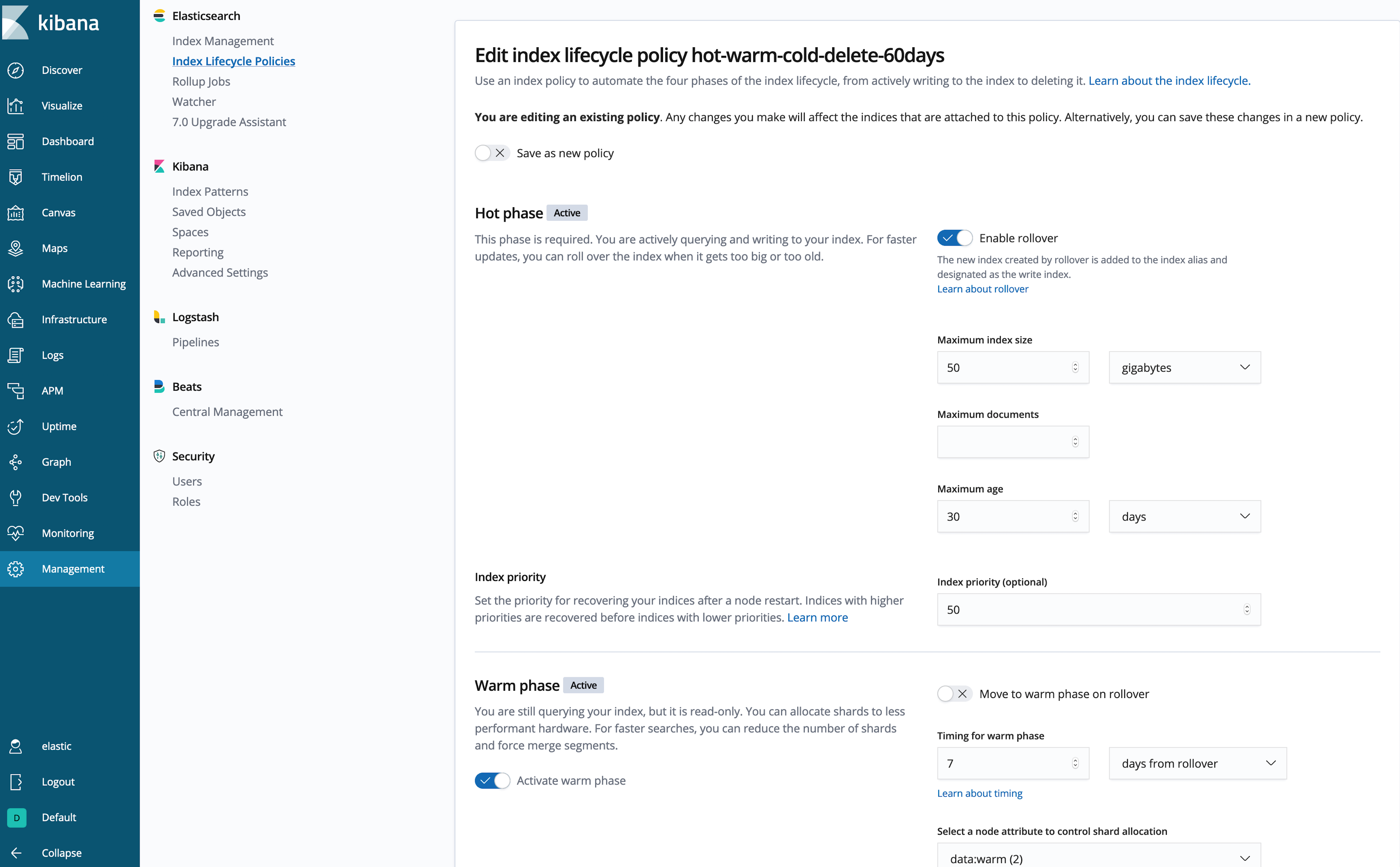
سپس باید سیاست داغ-گرم-سرد-حذف-60روزه را به نمایه هایBeatsوLogstashاختصاص دهیم و اطمینان حاصل کنیم که آنها در گره های داده داغ می نویسند.از آنجا کهBeatsوLogstashهرکدام الگوهای خاص خود را مدیریت می کنند(به طور پیش فرض)، ما قصد داریم ازچندینتطبیقالگوبرای افزودن خط مشی و قوانین اختصاصی استفاده کنیم که می خواهید به خط مشیILMاعمال کنید.از آنجا که این الگو با الگوهای شاخصBeatsوLogstashمطابقت دارد ، باید بدانید که می خواهید با کدام الگوهای شاخص مطابقت داشته باشید.در این مثال ما از”logstash- “،”metricbeat-“استفاده می کنیم”و” Filebeat- * “.با این وجود ، می توانید هر تعداد الگو که می خواهید اضافه کنید ، مشروط بر اینکه پشتیبانیILMدر پیکربندی مربوط بهBeatsیاLogstashفعال شود.اگر الگوهای شاخص را برای تولیدکننده داده هایی که ازILMپشتیبانی نمی کنند اضافه می کنید ، باید به صورت دستیپیش نیازهایبازپرداخت در این سیاست را برآورده کنید.
PUT _template/hot-warm-cold-delete-60days-template
{
"order": 10,
"index_patterns": ["logstash-*","metricbeat-*","filebeat-*"],
"settings": {
"index.routing.allocation.require.data":"hot",
"index.lifecycle.name":"hot-warm-cold-delete-60days"
}
}فعالسازیILM درBeatsوLogstash
در آخر ، بیاییدILMرا برایBeatsوLogstashفعال کنیم.
برایBeats :
output.elasticsearch:
ilm.enabled: trueبرایLogstash :
output {
elasticsearch {
ilm_enabled => true
}
}Logstash در ELk
Logstash یک فریم ورک جهت centralize کردن و ارسال و ذخیره سازی و یا تغییر ساختار داده می باشد. این فریم ورک می تواند داده ها را از سرور های مختلف جمع آوری، پردازش و نمایش دهد. برای ارسال داده به این فریم ورک می توان از ابزار هایمتنوعیاستفاده نمود. پس از جمع آوری داده توسط logstash برای ذخیره سازی، داده به ابزار های مختلف مانند elsticsearch فرستاده خواهد شد. تصویر زیر نمایی از این ارتباط را نشان میدهد. شما می توانید داده ها را بدون هیچ تغییری ذخیره سازی نمایید. اما ممکن است داده های شما همیشه مناسب ذخیره سازی نباشد و نیاز داشته باشید فقط داده های مهم را ذخیره نمایید. برای این منظور استفاده از logstash توصیه میشود.
در logstash دو مفهوم اصلی وجود دارد input و output. Input برای ارسال داده به logstash میباشد. همان طور که در تصویر بالا دیده میشود در اینجا وردی ما beat می باشد. خروجی داده در مدل ELK ابزار elasticsearsh می باشد. شما می توانید متناسب با نیاز خودخروجیداده های پردازش شده را تعیین کنید. این خروجی برای ذخیره سازی داده مورد استفاده قرار میگیرد.
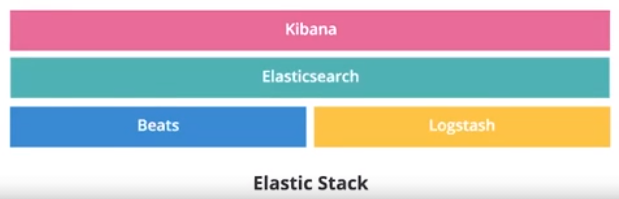
در تصویر بالا معماری elastic stack را مشاهده میکنید. در این معماری beat نقش ورودی و جمع آوری کننده اطلاعات را ایفا میکند. مدیریت و پردازش لاگ های جمع آوری شده بر عهده logstash بوده و داده های پردازش شده را برای elasticsearch ارسال کرده و kibana اطلاعات را نمایش میدهد.
دلیل استفاده سیستم از logstash به شرح ذیل می باشد:
- این فریم ورک یک سیستم بافرینگ بر اساس دیسک دارد که می تواند داده های ورودی فراوان را به خود جذب کرده و فشار داده را کاهش دهد.
- توانایی دریافت داده از منابع مختلف مانند دیتابیس، s3 و صف ها
- توانایی اسال داده به منابع مختلف مانند s3 ، HDFS و یا ذخیره آن بر روی فایل
- ایجاد پایپلاین های پیچیده برای کنترل جریان داده
سرویس beat و logstash ترکیب فوق العاده ای را ایجاد میکنند. ترکیب این دو یک سیستم قابل اعتماد و مقیاس پذیر خواهد بود.
- مقیاس پذیری افقی، دسترسی بالا و پشتیبانی از انواع مختلف loadbalancing
- قطعیت پیام، تضمین ارسال حداقل یک بار یک داده
- ارتباط امن بین سرویس ها
Beat بر روی نود های زیادی نصب میگردد و اطلاعات را جمع آوری کرده، تکه میکند و به logstash ارسال میکند. Logstash یک سیستم استریمینگ مرکزی فراهم کرده و داده ها را یک پارچه میکند. تصویر زیر نمایی از این ارتباط را نشان میدهد.
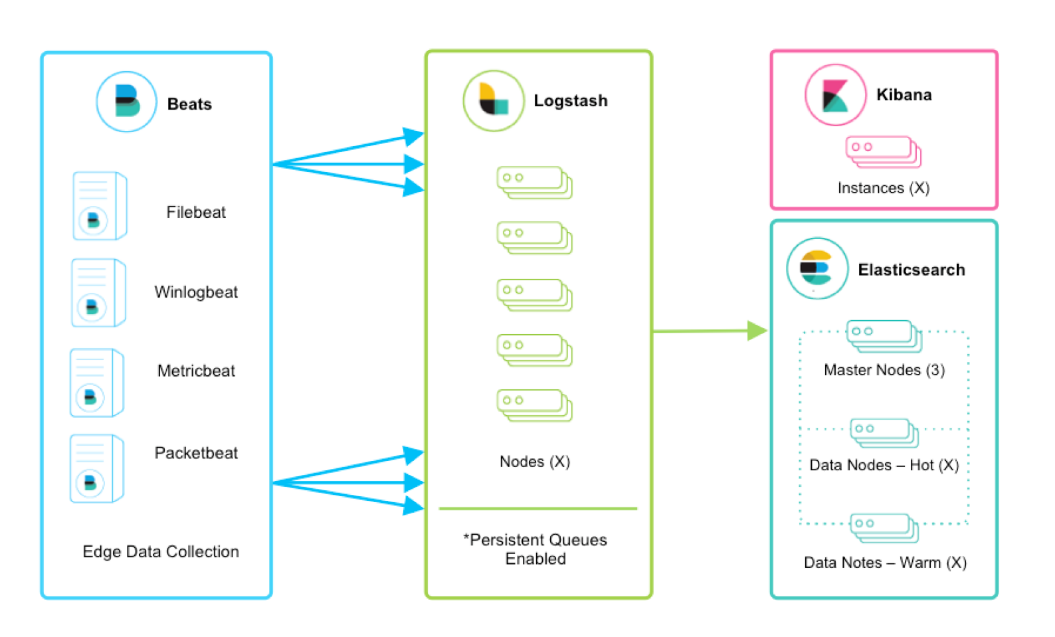
استفاده از صف مداوم در معماری استفاده شده توصیه میگردد برای اطلاعات بیشتر می توانید به اینصفحهمراجعه کنید.
Logstash می تواند به صورت افقی مقیاس شود و گروهی از نود های در حال اجرا را تشکیل دهد که یک جریان داده را دنبال میکنند. این ابزار از سیستم buffering استفاده میکند که می تواند جریان داده را یکنواخت کند حتی اگر ورودی های داده بار متفاوتی داشته باشند. اگر در معماری خود محدودیت از طرف logstash ایجاد شود می توانید این محدودیت شبکه را با افزودن نود جدید به آن مرتفع سازید.
- Beats بین نودهای مختلف loadbalance میگردد.
- حداقل دو نود logstash توصیه میشود.
- معمولا استفاده از یک سرویس beat برای نودهای logstash استفاده شود ولی امکان استفاده از چندین سرویس beat نیز وجود دارد (تصویر سرویس های beat در ابتدای مطلب)
زمانی که شما از filebeat یا Winlogbeatبرای جمع آوری لاگ ها استفاده میکنید. ارسال حد اقل یک بار هر لاگ تضمین شده میباشد. به این صورت که ارسال و دریافت داده ها به logstash و ارسال آن به elstic همگی همراه با پاسخ صحت دریافت همراه هستند. در دیگر سرویس های beat این ویژگی هنوز فعال نشده است.
صف مقاوم در سرویس logstash در مواقع خرابی نود ها از داده ها محافظت میکند. برای ذخیره سازی داده ها بر روی دیسک حتما پایداری داده ها را درنظر بگیرید (replicate or RAID) .
Logstash به طور رایج ازgrokوdissectبرای استخراج فیلد ها استفاده میکند و می تواند آن ها را برروی فایل یا دیتابیس یا elasticsearch ذخیره کند.
در logstash شما می توانید ورودی ها متفاوتی را داشته باشید. برای مثال استفاده از ورودی های بر پایه صف های پیام مانند kafka یا پروتکل های رایج مانند tcp. شکل زیر ساختار این نوع ارتباطات را نشان می دهد. توصیه می شود که از Redis یا RabbitMQ به جای صف پایدار خود logstash استفاده نشود تا بتوانید به راحتی سیستم را مدیریت کنید و تغییرات را به سرعت اعمال کنید. با این حال میتوانید از این ابزار ها به عنوان buffer ورودی برای logstash استفاده نمایید.
به صورت پیشفرض logstach داده های ورودی را در داخل رم زخیره میکند اما شما می توانید از persistent queue برای ذخیره سازی اطلاعات استفاده کنید که داده ها را بر روی دیسک ذخیره میکند. ساختار این ارتباط به شکل زیر می باشد.
input → queue → filter + output
توجه داشته باشید که تمام input ها در logstash از تایید حداقل یک بار ارسال لاگ پشتیبانی نمی کند.
برای مطالعه بیشتر در مورد مانیتورینگ شبکه با elk میتواند به این مقاله مراجعه کنید
Kibana
برای نمایش داده های خام نیازی به ابزاری خواهد بود تا بتوان این داده ها را به اطلاعات بصری جهت تحلیل رخداد های سیستم دسته بندی نمود. یکی از ابزار ها قدرت مند در این زمینه kibana است که می تواند با استفاده از فیلتر های مناسب نمودار های قابل درک از خروجی داده ها را ایجاد نماید. یکی از ویژگی های این ابزار تطابق آن با الگوهای کوری elasticsearch است که ارتباط با این ابزار را به راحتی مدیریت کرده و در قالب نموداد نشان خواهد داد.
یکی دیگر از قابلیت های این سرویس مدیریت هشدار میباشد تا درصورتی که رخدادی خارج از حد مشخص شده اتفاق بیوفتد ان را به سرعت گزارش دهد.
APM
Elastic APM یک سیستم نظارت بر عملکرد برنامه است که بر روی Elastic Stack ساخته شده است. این به شما امکان می دهد که اطلاعات دقیقی در مورد زمان پاسخگویی به درخواست های ورودی ، کويری های پایگاه داده ، call های حافظه پنهان ، درخواست های HTTP خارجی و موارد دیگر جمع آوری کنید و میتوانید سرویس ها و برنامه های نرم افزاری را به صورت real-time کنترل کنید. این کار باعث می شود مشکلات یک برنامه یا سرویس به سرعت مشخص و برطرف شود.
Elastic APM همچنین به طور خودکار خطاها و exception های کنترل نشده را جمع آوری می کند. خطاها اساساً بر اساس stacktrace گروه بندی می شوند ، بنابراین می توانید خطاهای جدید را هنگام ظهور شناسایی کرده و چندین بار خطاهای خاص را تحت نظر داشته باشید.
معماری أن به شکل زیر است
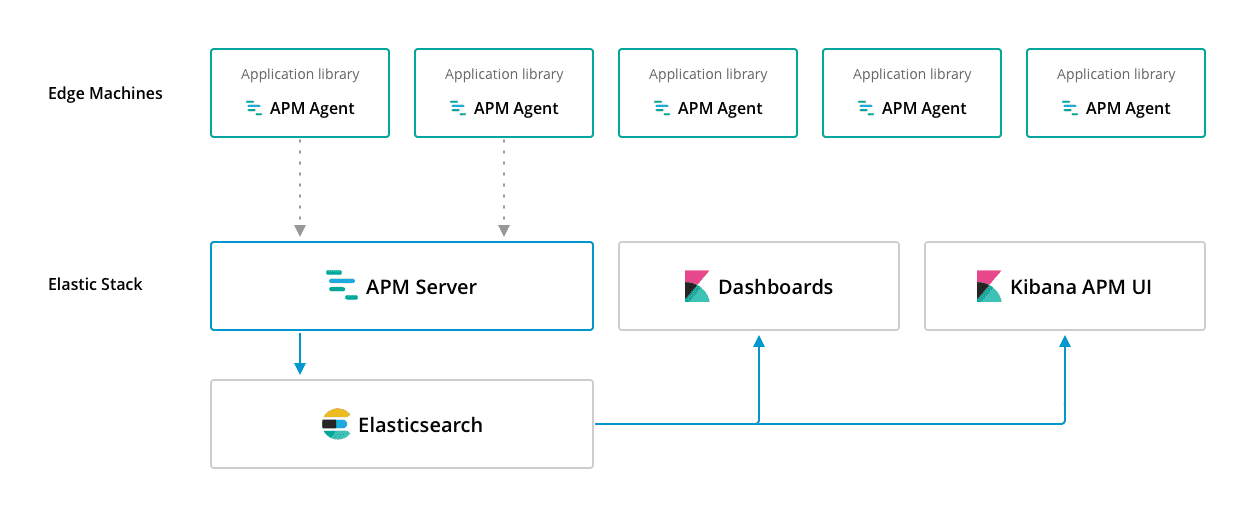
یک) APM Agents کتابخانه های متن باز هستند که به همان زبان برنامه شما نوشته شده اند. همانطور که کتابخانه دیگری را نصب می کنید ، آنها را در برنامه خود میبایست نصب کنید.
لیست این agent ها در لینک زیر قابل دسترس است
https://www.elastic.co/guide/en/apm/agent/index.html
دو) APM Server یک برنامه متن باز است که به زبان Go نوشته شده و بر روی سرورهای شما اجرا می شود. به طور پیش فرض روی پورت 8200 گوش می دهد و به طور دوره ای از agnet ها داده دریافت می کند.
برای visual کردن داده ها پس از ارسال آنها به Elasticsearch ، می توانید از داشبوردهای Kibana که به صورت pre-builtin در سرور APM هستند استفاده کنید.
فصل سوم مراحل نصبELK
مرحله اول: نصب elastic search
برای نصب elastic search مراحل زیر را در سرور مورد نظردنبال نمایید .
sudo apt-get install apt-transport-https
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.1-amd64.deb
sudo dpkg -i elasticsearch-7.9.1-amd64.deb
sudo /etc/init.d/elasticsearch startپس از نصب از فعال بودن سرویس مطمئن شوید به صورت پیش فرض سرویس بر روی پورت 9200 فعال می باشد.
نکته: قبل از نصب حتما از نصب java بر روی سیستم اطمینان حاصل نمایید. برای نصب جاوا می توانید از دستور زیر استفاده کنید.
apt install default-jreمرحله دوم: فرایند نصب logstash
Elastic Stack دارای 5نسخه مختلفمی باشد که از لحاظ feature ها بایکدیگر متفاوت هستند. نسخه opensource، نسخه basic و سه نسخه enterprise . در این مقاله در مورد نسخه basic آن و ویژگی هایی که در این نسخه وجود دارم بحث می نماییم.
برای نصب logstash می توانید از باینری آن استفاده کنید آدرس باینری را می توانید دراینجامشاهده نمایید.
همچنین شما می توانید از packet manager های خود سیستم عامل های لینوکس نیز برای نصب استفاده کنید. مراحل نصب با package manager سیستم عامل به شرح ذیل می باشد.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
sudo apt-get install apt-transport-https
echo "debhttps://artifacts.elastic.co/packages/7.x/aptstable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
apt-get update && sudo apt-get install logstashدر ادامه یک کانفیگ ساده در logstash را مشاهده میکنید. فایل کانفیگ در هر مسیری می تواند استفاده شود فقط زمان اجرا باید محل آن را به فایل باینری ارسال کرد. مسیر پیشفرض /etc/logstash است.
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index =>"%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user =>"elastic"
#password =>"changeme"
}
}همان طور که مشخص است کانفیگ ها در دوبخش input و output قابل تغییر هستند. به صورت کلی فایل کانفیگ در logstash به شکل زیر می باشد.
# This is a comment. You shoulduse comments to describe
# parts of your configuration.
input {
...
}
filter {
...
}
output {
...
}این کافنیگ از سه بخش input و output و filter تشکیل شده است. در بخش ورود ی شما میتوانید نام plugin ورودی مورد نظر خود را قرار دهید. در مثال قبلی پلاگین استفاده شده beat می باشد. شما می توانید چندین پلاگین مختلف را در قسمت ورودی داشته باشید.
input {
file {
path =>"/var/log/messages"
type =>"syslog"
}
file {
path =>"/var/log/apache/access.log"
type =>"apache"
}
}در مثال بالا ورودی فایل می تواند با type های مختلف از یکدیگر جدا شود.
input {
tcp {
port => 5000
type => syslog
}
udp {
port => 5000
type => syslog
}
}
filter {
if [type] =="syslog" {
grok {
match => {"message" =>"%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => ["received_at","%{@timestamp}" ]
add_field => ["received_from","%{host}" ]
}
date {
match => ["syslog_timestamp","MMM d HH:mm:ss","MMM dd HH:mm:ss" ]
}
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}در شکل قبلی ساختار پیچیده تری از کانفیگ ها را مشاهده میکنید. در این مثال ورودی ما plugin های tcp و udp می باشد. در قسمت filter ها می توانید بر اساس متغیر های داخلی خود logstash فیلتر های مورد نظر خود را اعمال کنید. در این مثال در صورتی که لاگ ها از نوع syslog باشد و ساختار آن با الگوی مشخص شده یکسان باشد در خروجی نمایش داده خواهد شد. در قسمت خروجی هم در بخش اول داده ها به elsticsearsh فرستاده می شود و در بخش دوم در خروجی stout نشان داده خواهد شد.
مرحله سوم: تنظیمات پلاگین های ورودی (beats)
همان طور که در قسمت قبلی نشان داده شد logstash هسته اصلی elk است و داده ها را از ورودی دریافت و بعد از فیلترینگ به خروجی منتقل میکند. در این قسمت به بررسی ورودی ها و مخصوصا beat خواهیم پرداخت.
در سناریو موجود openstack ما نیاز به دریافت اطلاعات از journal خواهد داشت. برای این منظور به طور مشخص از journalbeat استفاده میکنیم.
نصب این ابزار ساده می باشد پس از نصب باید در قسمت تنظیمات در فایل journalbeat.yml محل ذخیره سازی journal فایل ها را اعلام کنید.
مراحل نصب به این صورت می باشد:
curl -L -O https://artifacts.elastic.co/downloads/beats/journalbeat/journalbeat-7.9.2-amd64.deb
dpkg -i journalbeat-7.9.2-amd64.debjournalbeat.inputs:
- paths:
-"/dev/log"
-"/var/log/messages/my-journal-file.journal"
seek: headمثال بالا نمونه کانفیگ جهت خواندن لاگ های journal برای journalbeat می باشد. در قسمت path مسیر فایل های مورد نظر را وارد میکنیم. در قسمت output می توانید محل ارسال لاگ ها را مشخص کنید برای مثال logstash یا خود سرور elasticsearch می تواند به عنوان خروجی باشد. در صورتی که مسیر تعریف نشود ، مسیر پیش فرض journalctl انتخاب خواهد شد.
در خروجی می توانید آدرس elastic search یا سرور logstash را قرار دهید. برای فعال کردن این ویژگی در فایل کانفیگ /etc/journalbeat/journalbeat.yaml این خط را اضافه می کنیم.
output.logstash:
hosts: ["localhost:5044"]همان طور که مشاهده میکنید ساختار hosts ها آرایه می باشد و میتوان چندین خروجی برای beat درنظر گرفت. در این سناریو فرض بر این است که تمام سرویس ها بر روی یک سرور قرار دارند. بنابراین تمام endpoint ها با آدرس localhost می باشد.
مرحله چهارم: نصب و راه اندازی kibana
تمام سرویس های سمت سرور در elk نیاز به نصب jvm خواهند داشت. بنابراین در صورتی که تمام سرویس ها بر روی یک سرور باشند نیاز به نصب مجدد jvm نخواهد بود.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
sudo apt-get install apt-transport-https
echo "debhttps://artifacts.elastic.co/packages/7.x/aptstable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
apt-get update && apt-get install kibanaپس از پایان نصب از فعال بودن سرویس kinaba اطمینان حاصل نمایید. پورت پیش فرض این سرویس 5601 می باشد. در قسمت تنظیمات در مسیر /etc/kibana/kibana.yaml می توانید پورت های سرویس و سورس های ورودی را تغییر دهید نمونه فایل زیر مثالی در این مورد می باشد.
server.port: 5601
server.host:"0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]
cluster.name:"optional name" #any node with same cluster name join to getherدر این قسمت آدرس و پورت elasticsearch به عنوان ورودی معرفی شده است.
مرحله پنجم: اتصال به kibana و بررسی صحت ارتباط با elasticsearch
در این مرحله به ساخت داشبورد در کیبانا و ارتباط آن با elastic search خواهیم پرداخت. در ابتدا به پنل وب کیبانا متصل می شویم آدرس درخواست به شکل زیر می باشد.
http://<Ip-address>:5601
پس از لود شدن صفحه از برقراری ارتباط Elasticsearch و kibana مطمئن می شویم. برای این منظور از منوی تنظیمات kibana در قسمت manager بخش dev tools صحت ارتباط را بررسی میکنیم.
پس از کلیک در این قسمت صفحه ای مشابه با تصویر زیر نشان داده خواهد شد.
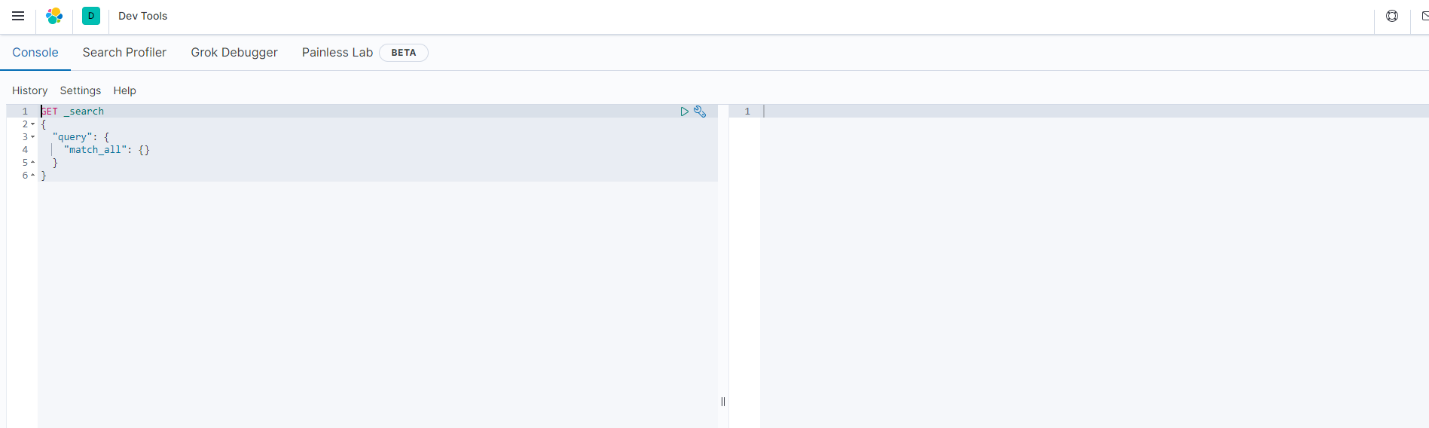
با کلیک بر روی گزینه play در صورت صحیح بودن ارتباط خروجی کوئری در سمت راست نشان داده خواهد شد.
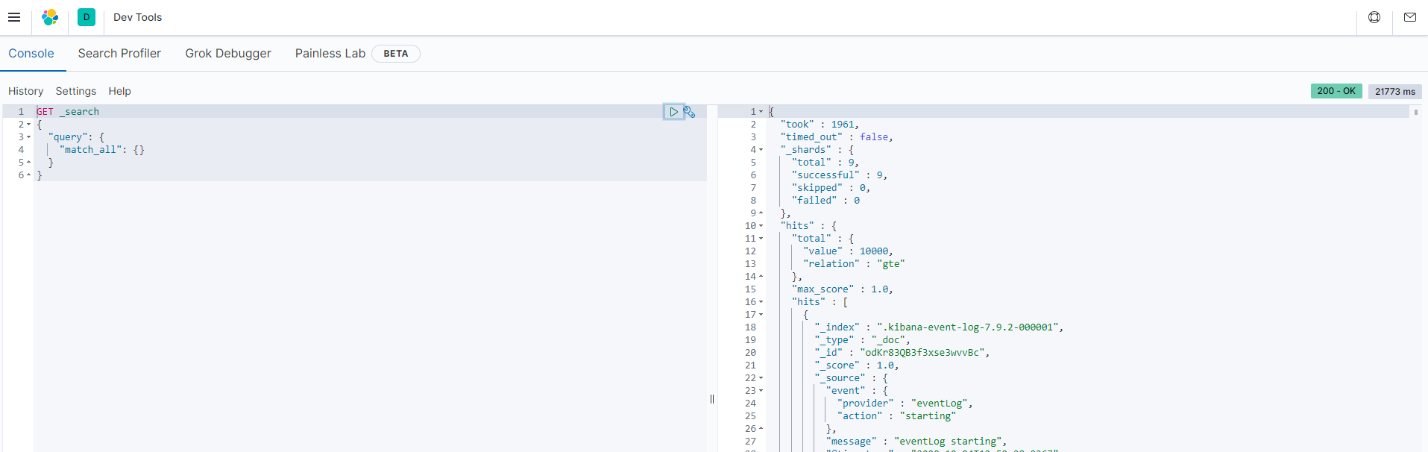
در صورتی که پاسخ درخواست ok باشد نشان گر صحت برقراری kibana با elasticksearch خواهد بود. پس از اطمینان از ارتباط به مرحله ساخت داشبورد می رسیم در این مرحله باید index های مورد نظر را ایجاد نماییم.
آنالیز لاگ در elsaticsearch
فرایند فیلترینگ
در Elasticsearch علاوه بر عملیات عادی هر database دیگر یا همان CRUD ابزار قدرتمندی جهت آنالیز متن وجود دارد. این ابزار شامل چهار ویژگی زیر می باشد.
- آنالیز ساده متن
- جستجو در داخل ساختار های داده
- اعمال کوئری های پیچیده
- جستجو در داخل متن کامل
جستجو در متن داده با داده های دیگر مانند عدد ، تاریخ و … متفاوت است. شما در داده های عددی می توانید تصمیمات قطعی بگیرد مثلا عدد مورد نظر از 10 بزرگتر باشد همیشه یک خروجی یکسان خواهد داشت. ولی در متن آنالیز متفاوت است. ما دو نوع متن داریم یا متن ما ساخت یافته است مانند شماره سریال دستگاه که ترکیب عدد و حروف است یا آدرس ها که ابتدا نام کشور سپس نام شهر و … خواهد بود. یا متن غیر ساخت یافته است که به آن متن کامل می گوییم.
آنالیز متن در elasticsearch در دومرحله انجام میشود. یک مرحله در زمان index گذاریست و مرحله بعد درزمان جستجو می باشد. شما می توانید لیست analyzer ها را دراین جامشاهده نمایید.
ساختار فیلترینگ را در تصویر زیر مشاهده میکنید
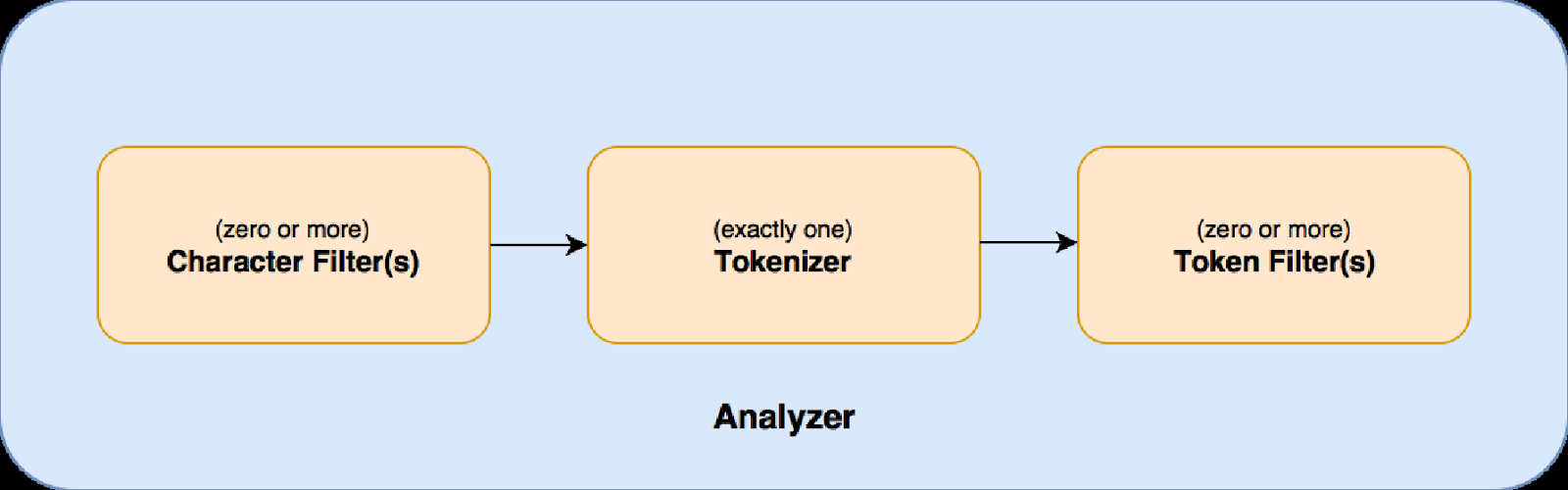
در مرحله اول جریان داده ورودی توسطفیلتر کاراکتردریافت شده و می توان با استفاده از آن داده را تغییر داد. برای مثال می توانید عدد هایی که به عربی ارسال شده است را به انگلیسی تبدیل کنید.
در مرحله دومtokenizerداده هارا دریافت کرده و آن ها را از هم تفکیک میکند برای مثال یک جمله را به کلمات تشکیل دهنده آن تفکیک میکنیم. در مرحله آخرtoken filterخروجی tokenizer را دریافت و آن ها را تغییر میدهد برای مثال می توانید کلمات را lowercase نمایید.
با یک مثال ساختار فیلتر را نشان میدهیم. جمله Good morning everyone 🙂 را در نظر بگیرید. می خواهیم 🙂 را تبدیل به smile کنیم . برای این منظور از فیلتر زیر استفاده میکنیم.
"char_filter": {
"my_char_filter": {
"type":"mapping",
"mappings": [
":) => _smile_",
":( => _sad_",
":D => _laugh_"
]
}
}در این جا از فیلتر mapping استفاده کرده و هر جریان داده در صورت تطابق با کارکتر های مورد نظر را تبدیل به کلمه نوشته شده در جلوی آن خواهد کرد. مثلا جمله قبلی تبدیل به این جمله خواهد شد:
Good morning everyone _smile_.و خروجی به مرحله بعد از فیلترینگ فرستاده میشود. یک مثال از tokenizer را در متن زیر مشاهده میکنید.
POST _analyze
{
"tokenizer":"standard",
"text":"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}در اینجا یک text ارسال شده و خروجی به شکل زیر تبدیل میگردد.
[ The, 2, QUICK, Brown, Foxes, jumped, over, the, lazy, dog's, bone ]در مرحله بعدی خروجی به فیلتر token filter ارسال می شود. در متن بعدی نمونه ای از اعمال این فیلتر را بر متن خروجی tokenizer مشاهده میکنید.
GET /_analyze
{
"tokenizer" :"standard",
"filter" : ["asciifolding"],
"text" :"açaí à la carte"
}پس از ارسال این فیلتر خروجی به شکل زیر خواهد شد.
[ acai, a, la, carte ]فرایند کوئری را در تصویر زیر مشاهده میکنید.
برای مطالعه بیشتر در مورد مانیتورینگ شبکه با elk میتواند به این مقاله مراجعه کنید
دوره مدیریت لاگ با elk میتواند برای درک بهتر بسیار مفید باشد – دوره مدیریت لاگ با ELK
امیدوارم مفید بوده باشه
یا حق
