راه اندازی کلاستر Redis روی کوبرنتیز
Redis دقیقا چیست؟
در واقع Redis یک ذخیره ساز ساختار های داده ای در RAM هست:) یعنی چی؟
ساختار های داده ای یا Data Structure می توانند یک رشته ساده و یا یک لیستی از داده ها باشند که Redis اونها رو توی RAM برای ما نگه داری می کنه و می تونیم با سرعت بالا اون ها رو بازیابی کنیم. از آنجایی که داده ها رو ذخیره و بازیابی می کند یک نوع دیتابیس هست و چون توی RAM نگه می داره اصطلاحا in-memory Database نام گزاری می شود.
اما برای هر داده ای که در Redis ذخیره می کنیم یک key یا کلید داریم و زمان بازیابی با استفاده از این key هست که به داده خودمون که همان value هست می رسیم و بنابر این Redis یک key value database هست.
پس Redis یک دیتابیس NoSql می باشد اما علاوه بر استفاده از Redis به عنوان دیتا بیس با توجه به ویژگی های اون که در ادامه پست ها با اونها کامل آشنا می شویم می توانیم Redis رو به عنوان Cache و Message Broker هم استفاده کنیم.
آیا نگه داری داده ها در RAM باعث از دست رفتن آنها نمی شود؟
خوب این سوالی هست که هر تازه کاری باید در ابتدا بپرسه! آیا از آنجایی که Redis داده ها را روی RAM نگه می دارد، بعد از خاموش و روشن شدن و یا هر اتفاق غیر قابل پیش بینی که بیافتد و RAM سیستم خالی شود داده های ما پاک می شوند؟
خیر، Redis برای نگه داری دائمی داده ها آنها را با توجه به تنظیماتی که ما برای آن مشخص می کنیم به دیسک اصلی سیستم منتقل می کند و بعد از پاک شدن RAM دوباره می تواند آنها را منتقل کند و کار را از سر بگیرد.
این ویژگی باعث شده اصطلاحا به آن on-disk persistence بگویند و این کار را می تواند در سطوح مختلفی انجام دهد. این سطوح شامل موارد زیر می شوند:
۱. روش RDB: اگر قصد back up گیری از داده های خود به صورت فایل های جداگانه در فاصله های زمانی مشخص و بعد از تعداد مشخصی تغییر را داشته باشید می توانید از این روش استفاده کنید و کافی است به Redis بگویید که در چه بازه های زمانی به صورت تکراری و تا چه مدت از داده ها back up بگیرد.
برای مثال هر ۳۰ دقیقه و به مدت ۳۰ روز از داده ها ی خود می توانید back up بگیرید و در هر زمان که مشکلی پیش آمد آنها را برگردانید. در واقع RDB مخفف Redis Database Backup می باشد به این معنی که هر بار از کل دیتا بیس یک dump می گیرد و نگه می دارد.
پس در این روش ممکن هست داده هایی رو از دست بدهید و اگر در لحظه داده های شما مهم هستند بهتر هست از روش بعدی استفاده کنید.
۲. روش AOF: این روش مخفف Append Only File هست به معنی اینکه یک بار فایل RDB را می سازد و با هر تغییر می تواند به آن فایل اضافه کند و به این صورت اگر چه شاید کمی کند تر باشد ولی برای داده های حساس تر گزینه بهتری هست.
این روش قادر است با استفاده از fsync بعد از هر بار درج و یا تغییر یک key جدید در Redis آن را ذخیره کند.
۳. غیر فعال کردن Persistence Mode به طور کلی و back up نگرفتن
۴. استفاده ترکیبی از RDB و AOF
مقایسه memcached و redis
از آنجایی که هر دوی این ها برای موارد مشترکی مانند cache می توانند استفاده شود همواره مقایسه ای بین آنها انجام می شود اما با توجه به تغییرات Redis در ورژن های بالاتر تقریبا انتخاب Redis امری بدیهی هست.
در پارامتر های زیادی از جنبه های مختلف می توان این دو رو بررسی کرد اما به طور خاص در این ۳ پارامتر که در ادامه اشاره می شود Redis کاملا برتر هست:
تفاوت بزرگ آنها در نوع داده هایی هست که نگه می دارند. memcached فقط توانایی ذخیره نوع ساده رشته را به عنوان مقدار دارد در صورتی که Redis دارای ۵ نوع Data Type اصلی هست که در پست بعدی با آنها آشنا خواهیم شد. از آنجایی که Redis دارای Data Type های بیشتری هست استفاده از آن می تواند باعث سهولت در نگه داری ساختار های داده ای پیچیده تر و کاربرد های متفاوت تری بشود. تفاوت بعدی در بحث Memory usage هست که Redis عملکرد بهتری داد به خصوص در بحث آزاد سازی سریع فضای RAM استفاده شده بعد از flush کردن داده ها.
مورد بعدی persistence هست که همان طور که در بالا دیدیم Redis به صورت پیش فرض در خودش مکانیزم های کاملی برای آن دارد در صورتی که Memcached نیاز به ابزار های 3rd party برای dump گرفتن داده ها دارد. البته ناگفته نماند که در بعضی موارد هم مانند سرعت خواندن و نوشتن و یا Scaling این دو بسیار به هم نزدیک هستند و برتری خاصی حس نمی شود.
چند مورد بیشتر در مورد Redis که باید بدانیم:
-
با زبان C نوشته شده است
-
از Lua Scripting پشتیبانی می کند
-
به صورت پیش فرض replication دارد
-
دارای partitioning از طریق Redis Cluster هست
-
پورت پیش فرض اون 6379 هست
-
به صورت open source و تحت License BSD نگه داری می شود
خوب همون طور که اشاره کردیم Redis یک دیتابیس NoSql است که علاوه بر استفاده به عنوان دیتا بیس با توجه به ویژگی های اون می توانیم Redis رو به عنوان Cache و Message Broker هم استفاده کنیم. در ادامه بهتون میگیم که چطور یک کلاستر Redis روی کوبر پیاده سازی کنید.
توپولوژی کلاستر
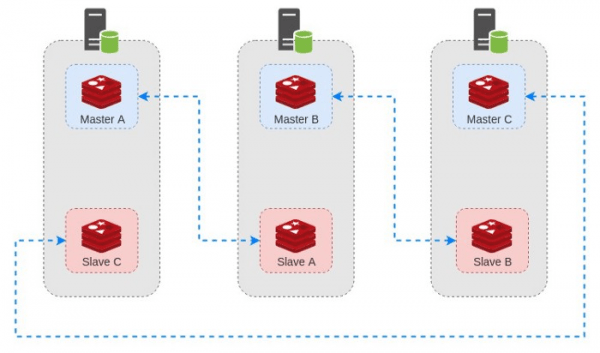
در ابتدا به تعداد و ترکیب Worker ها می پردازیم. چیزی که Redis پیشنهاد کرده اینطوره :
-
۳ سرور مجزا
-
کانفیگ ۳ Master Node روی هر دستگاه
-
کانفیگ ۳ Slave Node به ازای هر Master
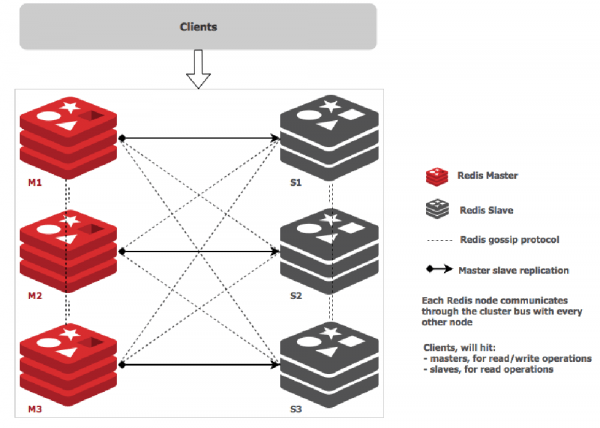
کلاسترینگ Redis از یک روش توزیع شده برای مرتب سازی داده ها در حافظه استفاده میکنه به این صورت که 16384 اسلات را بین کل Node ها تقسیم میکنه و برای اینکه هر اسلات جداگانه شناسایی بشه از CRC16 استفاده کرده و Hash هرکدام مشخص میشه. در نهایت هر Node وظیفه داره تا بازه مشخصی از اسلات ها رو مدیریت کنه. برای مثال ٬ یک کلاستر با ۳ نود به اینصورت عمل میکنه :
-
نود اول : شامل هش های بین 0 تا 5000
-
نود دوم : شامل هش های بین 5001 تا 10000
-
نود سوم : شامل هش های 10001 تا 16383
در نهایت چنین ترکیبی باعث میشه تا بدون هیچ downtime بتونیم نود های مختلف رو در سطح کلاستر اضافه یا حذف کنیم.
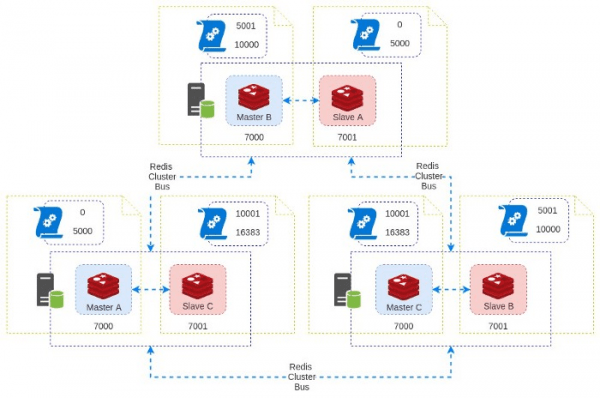
روند Fail-Over
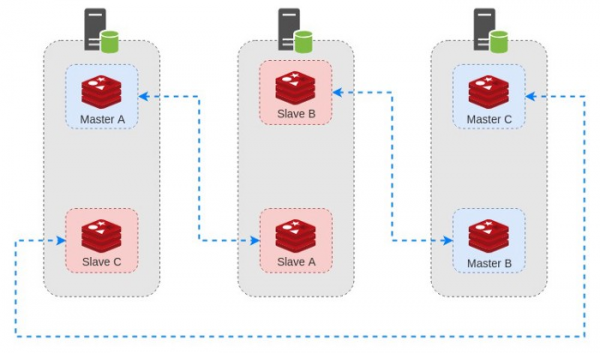
همین توپولوژی که الان توضیح داده شد در نظر بگیرید ٬ چنین دیاگرامی خواهیم داشت :
هرگاه یکی از سرور ها دارای مشکل شده و از شبکه خارج بشه ٬ کلاستر به طور خودکار یکی از Slave ها رو به Master تبدیل میکنه. فرض کنید در همین دیاگرام ٬ سرور دوم از دسترس خارج بشه :
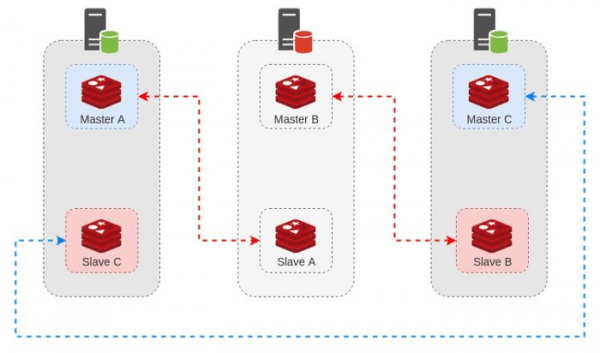
وقتی کلاستر تشخیص بده که Master B در دسترس نیست ٬ روند FailOver انجام میشه و Slave B رو به عنوان Master جدید قرار میده :
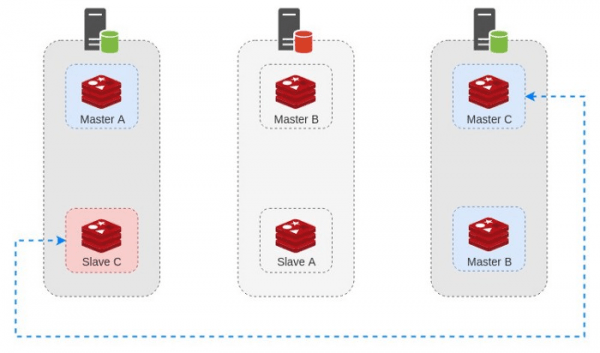
وقتی که مشکل برطرف بشه و سرور دوم مجددا به روند قبلی خودش برگرده ٬ کلاستر مجددا به روزرسانی شده و سرور به مجموعه بر میگرده :
توجه کنید که در این حالت ٬ یک شرایط ویژه و خطرناک رخ میده. چرا که اگر به دیاگرام بالا دقت کنید ٬ با اینکه همه ی اجزا وجود دارن ولی دیگه سر جای خودشون نیستن. حالا ما ۲ نود Master در یک سرور داریم که اگر اون سرور ( سرور اول ) از کار بیوفته با مشکلات بیشتری مواجه میشیم.
پیاده سازی کلاستر در Kubernetes
حال که با توپولوژی و نحوه کار کلاستر Redis آشنا شدیم ٬ پیاده سازی اون رو بررسی می کنیم. راه های زیادی برای این کار وجود داره ( فعلا برای آزمایش و محیط توسعه ) برای مثال میتونیم 6 ماشین مجازی بسازیم یا ۶ کانتینر داکر یا اگر زیرساختش موجوده و میخواید خیلی دل به کار بدید روی 6 سرور فیزیکی مجزا :)))
از نسخه 3 به بعد که قابلیت کلاسترینگ به Redis اضافه شد ٬ برای مباحث ایجاد یا ویرایش و تغییر اندازه ی کلاستر کتابخانه ای هم به نام redis-trib منتشر شد. حالا پس از گذشت چند نسخه ٬ دیگه نیازی به این برنامه نیست و تمام تنظیمات مربوط به کلاستر از طریق CLI پیش فرض در دسترس شماست. به علت وجود الگوی stateless در ساختار کوبرنتیز ٬ کمی سخت میشه که کلاستر Redis با توپولوژی ذکر شده طراحی و مدیریت کرد چون هر Instance از این کلاستر شامل فایلی میشه که اطلاعات مربوط به کلاستر و باقی نود ها رو هم تو خودش ذخیره میکنه و در نتیجه باعث میشه تا کل Instance ها از وضعیت هم باخبر بشن.
این یعنی در حین طراحی کلاستر باید حالت ویژه ای رو در نظر بگیریم تا این امر به درستی انجام بشه و راه حلش هم استفاده ترکیبی از StatefulSets و PersistentVolumes است.
فایل های مربوط به پیاده سازی به شکل زیر می باشد.
لینک دانلود فایل های منیفست مورد نیاز برای ردیس redis
همانطور که قبلا توضیح داده شد ٬ برای این کلاستر نیاز به 6 نود داریم که ۳ تای آن ها به صورت Master و ۳ تای دیگه به عنوان Slave عمل میکنن.
وقتی یک StatefullSet ایجاد می کنیم ٬ نتیجه گروهی از Instance های مجزای Redis میشه که با توجه به تنظیماتی که جلوتر توضیح میدم ٬ هرکدوم از این نود ها در حالت کلاستر یا Cluster Mode اجرا میشن.
علاوه بر این ٬ هرکدوم از اون ها درخواست یک Volume مجزا برای ذخیره سازی داده هاشون دارن که این کار از طریق PersistentVolumeClaim انجام میشه. تمامی روند تخصیص volume همانطور که تو فایل بالا مشاهده می کنید در بخش volumeClaimTemplates به صورت خودکار اتفاق میوفته.
جهت کار با کلاستر به دو فایل config نیاز داریم که این کار از طریق ConfigMap انجام میشه.
فایل اول به نام update.sh : یک اسکریپت ساده است که در هر مرحله آدرس آی پی Pod فعلی را دریافت کرده و با توجه به اون فایل تنظیمات کلاستر که در مسیر data/nodes.conf/ وجود داره رو به روزرسانی میکنه. فایل دوم به نام redis.conf : فایل تنظیمات پیشفرض Redis بوده که با توجه به نوع پیاده سازی و شرایط میتونید تغییرش بدید. توجه داشته باشید که تنظیمات مربوط به فعالسازی کلاستر و فایل مربوط به اون در این بخش قرار داره.
باکمک دستورات زیر این سرویس و پاد مربوط به این سرویس رو ایجاد میکنیم.
kubectl apply -f redis-sts.yaml
kubectl apply -f redis-svc.yamlتا اینجای کار ما 6 نود مجزا داریم که به درستی کانفیگ شده و کار می کنن. هرکدوم از اونها هم Volume اختصاصی خودشون رو دارن تا اطلاعات مربوط به کلاستر رو برای پیاده سازی توپولوژی ذکر شده ٬ ذخیره کنن.
حالا باید کلاستر اصلی رو تنظیم کنیم. اینجا از دستور redis-cli –cluster استفاده می کنیم. روش کار به این صورته :
redis-cli --cluster create --cluster-replicas <Replica count> <Node list>
از اونجایی که قراره 3 Master با 3 Slave مجزا داشته باشیم مقدار replicas برابر با 1 خواهد بود. ابتدا باید لیست نود ها رو به دست بیاریم. برای این کار از چنین دستوری استفاده می کنیم :
kubectl get pods -l app=redis-cluster -o jsonpath='{range.items[*]}{.status.podIP}:6379 'خروجی این دستور لیست ip:port شامل کل نود های ماست. از اونجایی که قبلا از label مناسب برای Pod هامون استفاده کردیم ٬ شناسایی اونها ساده تر میشه.
نکته مهم : در انتهای رشته یک کارکتر خالی وجود داره. برای جداسازی لیست نود ها ازش استفاده میشه. فکر نکنید اشتباهی رخ داده و اون رو پاک کنید :))
حالا کافیه دستور redis-cli –cluster create رو اجرا کنیم :
kubectl exec -it redis-cluster-0 -- redis-cli --cluster create --cluster-replicas 1 <<node-list>>در قسمت «node-list» باید لیست نود هایی که از دستور قبل به دست آورده اید را قرار دهید. در صورت لازم این دو دستور رو میتونید ادغام کنید :
kubectl exec -it redis-cluster-0 -- redis-cli --cluster create --cluster-replicas 1 $(kubectl get pods -l app=redis-cluster -o jsonpa
th='{range.items[*]}{.status.podIP}:6379 ')خروجی دستور چنین چیزی است :
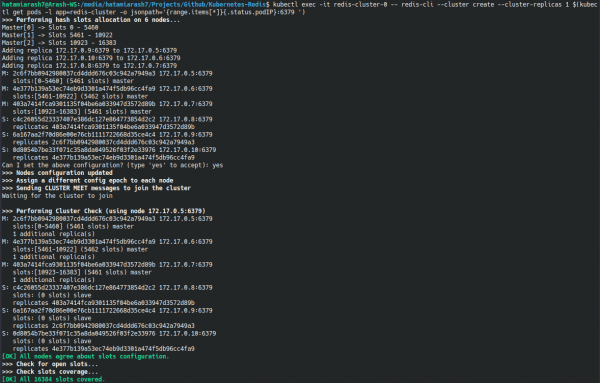
همینطور که مشاهده می کنید بحث تخصیص اسلات ها هم برای شما نمایش داده شده.
برای بررسی کلاستر و وضعیت هر پاد دستور زیر استفاده میشود
kubectl exec -it redis-cluster-0 -- redis-cli cluster info
or for all of them at once
for x in $(seq 0 5); do echo "redis-cluster-$x"; kubectl exec redis-cluster-$x -- redis-cli role; echo; doneپیاده سازی کلاستر در Kubernetes بکمک helm
Bitnami برای کابران کوبرنتیز چارت های آماده ای برای سرویس ها فراهم میکند. یکی از این چارت ها Bitnami Redis chart می باشد که به طور پیشفرض یک کلاستر با ۴ نود بهمراه data persistence روی همه نود ها به کمک replication ارایه میدهد. این چارت شامل ۲ فایل پیکربندی می باشد.
-
values.yml: مناسب برای تست و ایجاد کلاستر با یک نود
-
values-production.yml: مشخص کردن پارامتر های محیط پروداکشن با ایجاد تعداد ۴ نود کلاستر به طور پیش فرض
فایل values-production.yml دارای تعداد زیادی پارامتر برای پیکربندی می باشد که به شما امکان بالا آوردن سریع یک کلاستر ردیس را میدهد. پارامتری هایی مانند تعداد slave ها ، فعال سازی Sentinel برای high-availability و …
در ادامه به بررسی ساخت این نوع کلاستر به کمک helm می پردازیم.
موارد مورد نیاز:
-
ی کلاستر آماده کوبرنیتیز
-
نصب بودن پکیج kubectl
-
نصب بودن پکیج helm v3.x
برای شروع پردازش نیاز به فایل values-production.yaml می باشد که در حین ساخت کلاستر می بایست به دستور helm به عنوان ورودی مقدار دهی شود. این فایل می بایست دانلود و بر اساس نیاز خود تغییرات را روی آن اعمال کنید. بدین منظور دستور زیر را می زنیم.
curl -Lo values-production.yaml https://raw.githubusercontent.com/bitnami/charts/master/bitnami/redis/values-production.yamlبعد از دانلود، فایل را با ادیتور دلخواه باز و ویرایش کنید مثلا برای فعال سازی Sentinel نیاز است مانند زیر به بخش sentinel رفته و آن را enable کنیم.
## Use redis sentinel in the redis pod. This will disable the master and slave services and
## create one redis service with ports to the sentinel and the redis instances
sentinel:
enabled: true
.
.
. خوب بعد از ویرایش این فایل می بایست repository مربوط به bitnami را به helm اضافه کنیم.
helm repo add bitnami https://charts.bitnami.com/bitnami
بعد از اضافه کردن به کمک دستور زیر کلاستر را بالا میاوریم.
helm install redis bitnami/redis --values values-production.yaml
مقادیر پیشفرض روی یک کلاستر با ۴ نود اصلی ، تعداد ۵ پاد ارایه میدهد که یک مستر ، سه اسلیو و یکی اضافی برای metric ها می باشد.
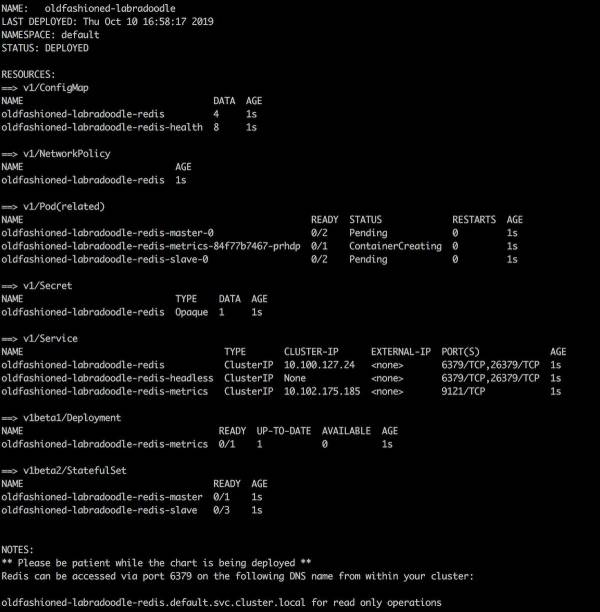
با دستور زیر اگه وضعیت را چک کنیم خروجی مانند تصویر زیر میشود.
kubectl get pods
بررسی دیتا رپلیکیشن در کلاستر ردیس
این کلاستر به طوری پیکربندی شده که مستر توانایی read , write را دارا می باشد و اسلیوها به حالت فقط خواندنی اند.وقتی دیتایی به نودمستر میرسد سریع بین اسلیو ها رپلیکیت می شود. برای تست می توانیم مراحل زیر را طی کنیم. برای دسترسی به نود مستر میبایست ی پاد جدا به عنوان ردیس کلاینت اضافه کنیم.بدین منظور از دستور زیر استفاده میکنیم.
kubectl run --namespace default DEPLOYMENT-NAME-redis-client --rm --tty -i --restart='Never' --env REDIS_PASSWORD=$REDIS_PASSWORD --labels="redis-client=true" --image docker.io/bitnami/redis:5.0.5-debian-9-r141 -- bashبه جای DEPLOYMENT-NAME می توانید از نام دلخواه استفاده کنید.
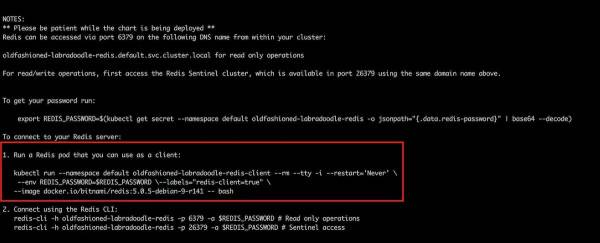
این چارت یک سرویس headless برای دسترسی داخلی ایجاد می کند که برای اتصال به نود مستر می بایست به نام این سرویس را به کمک دستور زیر درآورد.
kubectl get svcخروجی یک چیزی مانند زیر است.

برای دسترسی به نود مستر دستور redis-cli به صورت زیر اجرا میشود
redis-cli -h POD-NAME.HEADLESS-SVC-NAME -a $REDIS_PASSWORDحال با دستور info می توانید گزارش کامل را مشاهده کنید
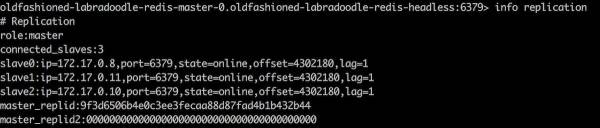
برای تست رپلیکیشن یک مقداری را ست می کنیم.
> set foo hello world
OK
> get foo
"hello world"حال به یک نود اسلیو متصل و مجدد چک کنین مقدار رو
redis-cli -h POD-NAME.HEADLESS-SVC-NAME -a $REDIS_PASSWORD> get foo
"hello world"
امیدوارم مفید بوده باشه یا حق

{kind=link}
{kind=link}
{kind=link}