بررسی و ساخت گلاستر اف اس (Glusterfs)

Gluster Storge چیست؟
Red Hat Gluster Storage، یک پلتفرم ذخیرهسازی باز، نرمافزارمحور و scale-out، جهت مدیریت آسان دادههای بیساختار برای محیطهای فیزیکی، مجازی و Cloud میباشد. درواقع Red Hat Gluster Storage، تلفیقی از ذخیرهساز File و Object با معماری scale-out می باشد، که جهت ذخیرهسازی و مدیریت مقرونبهصرفهی رشد دادههایی با مقیاس پتابایت (petabyte) طراحی شده است. Red Hat Gluster Storage، یک بافت ذخیرهسازی مداوم در منابع فیزیکی، مجازی و Cloud ارائه میدهد، تا مشتریان بتوانند دادههای بزرگ، نیمهساختارمند (Semi-Structured) و بیساختار (Unstructured) خود را از یک بارِ اضافه به یک سرمایه تبدیل نمایند.
Red Hat Gluster Storage جهت ذخیرهسازی انواع مختلف دادههای بیساختار استفاده میشود که از آن جمله می توان به موارد زیر اشاره نمود:
-
محتوای غنی رسانهای مانند فایلهای ویدئویی، عکسها و فایلهای صوتی
-
Backup-imageها و آرشیوهای Nearline
-
Big Data: فایلهای Log، دادههای RFID و سایر دادههای تولیدشدهی ماشینی
-
Imageهای ماشین مجازی
Red Hat Gluster Storage را میتوان به سادگی بهصورت on-premise در زیرساختهایPublic Cloud و محیطهایHybrid Cloud استفاده نمود. همچنین این محصول جهت ذخیرهسازی فشرده Workloadهای شرکتی مانند Archiving و Backup، ارائهی محتوای غنی رسانهای، Drop-Box شرکتی، برنامههای Cloud و کسبوکار، ذخیرهسازی زیرساخت مجازی و Cloud و همچنین workloadهای نوظهوری مثل برنامههایCo-resident وBig Data Hadoop workload بهینهسازی شده است.
مزایای استفاده از گلاستر
امروزه، شرکتها اغلب با siloهای ناهمگون ذخیرهسازی روبررو میباشند، که از نظر جغرافیایی در دیتاسنترهای زیادی در سرتاسر جهان پراکندهاند. Red Hat Gluster Storage به شرکتها اجازه میدهد siloهای خود را حذف کرده و دادههای خود را با تدارک و مدیریت ذخیرهسازی، بدون در نظر گفتن این موضوع که on-premise، مجازی، یا در یک زیرساخت Public Cloud باشد، یکپارچه نمایند.
هر شرکتی میتواند وابستگی خود به Arrayهای ذخیرهساز یکپارچه (Monolithic Storage) و پرهزینه که مقیاسبندیشان سخت است را کاهش دهد. با Red Hat Gluster Storage سازمانها میتوانند به راحتی از سختافزار Commodity ظرف چند دقیقه برای ذخیرهسازی مقیاسپذیر و با عملکرد بالا در دیتاسنترهای یا محیطهای Hybrid Cloud استفاده نمایند.
Red Hat Gluster Storage: یک راهکار ایدهآل برای Private Cloud
یک پلتفرم ذخیرهسازی باز، نرمافزارمحور و scale-out شده، که ظرف چند دقیقه، استاندارد صنعتی سختافزار x86 را ارائه میدهد.
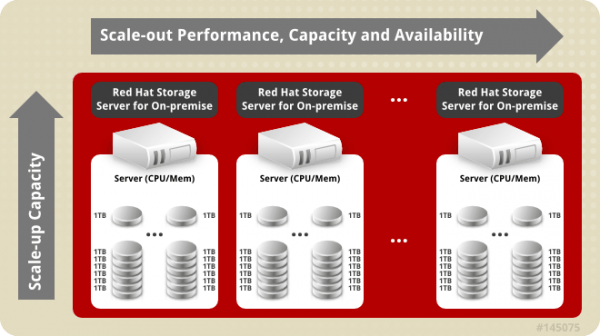
مقیاسپذیری و انعطافپذیری بدون ایجاد اختلال
Red Hat Gluster Storage برای مقیاسپذیریهای نامحدود طراحی شده است؛ در واقع با استفاده از این تکنولوژی لینوکسی، میتوان Storage را در عین دسترسپذیری دادهها، حذف یا اضافه نمود. تشخیص Bit-rot به تضمین یکپارچگی این دادهها کمک میکند و علاوه بر آن، معماری ارتجاعی و scale-out در Red Hat Gluster Storage به کاربران اجازه گسترش یکپارچه ذخیرهسازی را میدهد تا پاسخگوی نیازهای پویای محیطهای مجازی باشد.
نحوه گسترش آسان
یک ISO image جهت گسترش سریع، روی یک سرور یا Hypervisor های تحت پشتیبانی (مثلاً Red Hat Enterprise Virtualization و VMware vSphere/ESXi) نصب میشود.
عملکرد بهتر با هزینهی کمتر
Red Hat Gluster Storage از یک الگوریتم Hashing ارتجاعی استفاده مینماید تا با انجام محاسبات یک Hash روی Filename، دادهها را درStorage Pool مکانیابی نماید و منبع مشترکِ I/O Bottleneckها و آسیبپذیری دربرابر خرابی را از بین ببرد. این امر در کنار مقیاسپذیریِ ظرفیت بالا، برای کاربران عملکردی بهتر با هزینهای کمتر فراهم میسازد. دلیل دیگر کاهش هزینهها کدگذاری Erasure Coding است که الزامات ظرفیتی برای آرشیوها وCold Storage را، با هزینهی کمتر در هر گیگابایت، به وجود می آورد.
استفاده از Red Hat Gluster Storage در Hybrid Cloud
استفاده از Red Hat Gluster Storage در تکنولوژی Hybrid Cloud انعطافپذیری بسیار بالایی به سازمانها، در استفاده از Cloudهای Public و Private ارائه میدهد و این به دلیل آن است که Red Hat Gluster Storage یک نرم افزار ذخیره سازی باز، Scale-Out برای محیط های Hybrid Cloud محسوب می گردد.
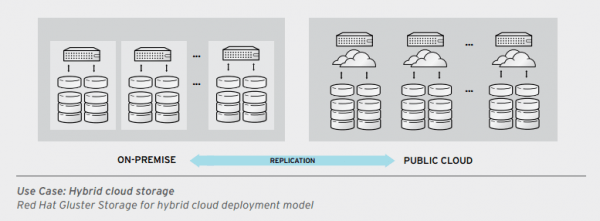
یکسان سازی داخلی (Built-In) جهت حفاظت از دادهها
Red Hat Gluster Storage برای Hybrid Cloud از Replication (یکسانسازی) استفاده می نماید تا در سراسر دیتابیس و Public Cloud دسترسپذیری (HA) بالا ایجاد کند. یکسانسازی همگام فایل ها، یک برنامهی دادهی Local ایجاد میکند که از تداوم کسبوکار پشتیبانی مینماید. یکسان سازی ناهمگام، Replication داده ها را در فاصلهی طولانی، به منظور فراهم نمودن Disaster Recovery امکان پذیر می سازد.
قابلیتهای کلی استفاده از Red Hat Gluster Storage
یک NameSpace سراسریِ واحد
این تکنولوژی منابع دیسک و حافظه را در یک Storage Pool مطمئن جمعآوری مینماید.
دسترسی Object به ذخیرهساز فایل
میتوان با استفاده از Object-APIنیز، به ذخیرهسازی فایل دسترسی یافت.
یکسان سازی یا Replication
از یکسانسازی همگام، داخل یک پایگاهداده و یکسانسازی ناهمگام، برای Disaster Recovery (بازیابی بحران) پشتیبانی مینماید.
کدگذاری حذف (Erasure Coding)
تقویت نمودن حفاظت از دادهها، با استفاده از اطلاعات ذخیرهشده در سیستم جهت بازسازی دادههای ازدسترفته یا آسیبدیده.
تشخیص Bit-rot
کمک به حفظ یکپارچگی داراییهای دادهای، با تشخیص آسیبدیدگی خاموش.
Tiering
انتقال خودکار دادهها بین ردیف های سریع (SSDمحور) و کند (HDD) بر اساس بسامد دسترسی.
امنیت
پشتیبانی از حالت اجرای SELinux با کدگذاری SSLمحورِ در حین حرکت
Snapshotها
تضمین نمودن حفاظت دادهها از طریق Snapshotهای فایل سیستمی بهوسعت کلاستر و همچنین دسترسی کاربری جهت بازیابی آسان فایلها.
الگوریتم ارتجاعی Hashing
نبود لایهی Metadataی سرور، Bottleneckهای سرور و تک نقطههای خرابی (Single Points of Failure) را از بین میبرد.
مدیریت سادهی آنلاین
-
کنسول مدیریت مبتنی بر وب
-
CLI قوی و شهودی برای مدیران Linux
-
مانیتورینگ (Nagiosمحور)
-
Expand/shrink نمودن ظرفیت ذخیرهسازی بدون Downtime
پشتیبانی کلایت با استاندارد صنعتی
-
پروتکلهای NFS و SMB برای دسترسی فایلمحور
-
پشتیبانی چندجانبه (multi-headed) NFSv4 برای افزایش امنیت و خودترمیمی
-
پشتیبانی OpenStack Swift جهت دسترسی به Object
-
GlusterFS native client جهت دسترسی بهشدت موازیشده
یکپارچهسازی با Red Hat Enterprise Virtualization
-
دید متمرکز و مدیریت یکپارچهی ذخیرهسازی و زیرساختهای مجازی از طریق کنسول مدیریت Red Hat Enterprise Virtualization
-
انجام Live Migration برای ماشینهای مجازی
یکپارچهسازی عمیق Hadoop
-
فایلسیستم سازگار با HDFS زمان اجرای انتقال داده را به صفر میرساند.
-
بدون نقطههای خرابی (Single Points of Failure)
-
جذب داده برمبنای NFS و FUSE
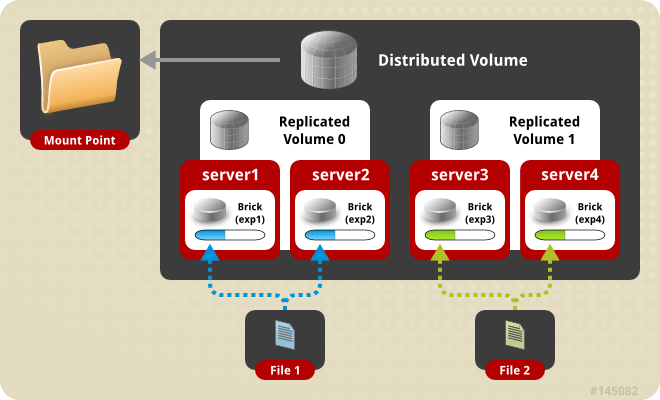
volume ها مجموعه ای از brick های منطقی هستند که هر brick بعنوان یک دایرکتوری اکسپورت شده از یک سرور درون trusted storage pool می باشد.
گلاستر اف اس دارای انواع مختلفی از volume ها می باشد
که در ادامه به بررسی آن ها می پردازیم.
انواع volume ها در گلاستر استوریج
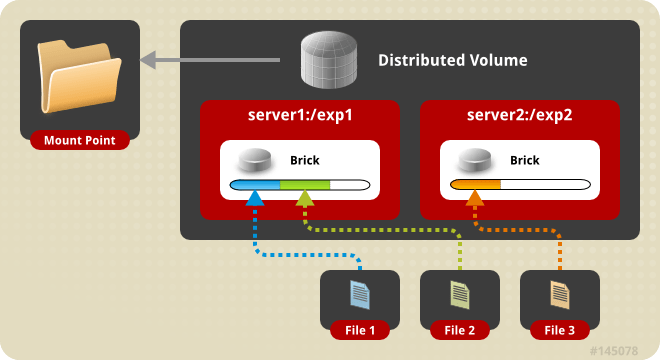
- Distributed
این مدل، فایل ها را بین bricks ها پخش می کند و برای افزایش مقیاس حجمی داده استفاده میشود سرعت نسبتا بالایی دارد ولی در آن redundancy وجود ندارد یا توسط لایه سخت افزاری/نرم افزاری دیگری انجام میشود.
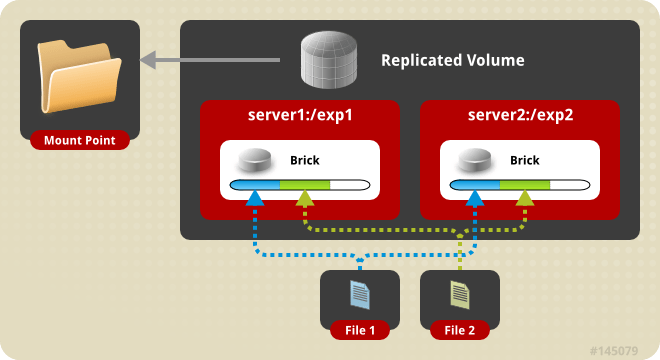
- Replicated
در این مدل داده ها بین bricks ها تکرار میشود از این مدل برای جاهایی که high-availability و high-reliability اهمیت بالایی دارد استفاده میشود
- Distributed Replicated
این مدل از ادغام دو مدل قبلی بدست می آید و در آن داده بین نودهایی که آیینه ی یکدیگراند پخش میشود.
این مدل خیلی پر استفاده است و بهره وری read را در محیط بالا می برد
- Dispersed
این مدل بر پایه کد های هک شده ای است که فضایی مفیدی را برای حفاظت از خطا یا از دست روی دیسک یا سرور فراهم میکند.به صورتی که یک بخش کدگذاری شده از فایل اصلی در هر brick ذخیره میشودکه به کمک آن می توان داده را در صورت ازبین رفتن بازیابی کرد . تعداد brick هایی که می تواند در صورت خطا بازیابی شود توسط ادمین در حین ساخت این ولیوم ایجاد میشود.
حجم مورد استفاده نهایی از طریق فرمول زیر حساب میشود. هرجه مقدار redundancy بالا باشد حجم مصرفی نیزز کمتر خواهد شد.
<Usable size> = <Brick size> * (#Bricks - Redundancy)
این بخش یکسری پیشنیازی هایی دارد به عنوان مثال :
- همه نود ها می بایست به یک اندازه فضا داشته باشند
- حداقل تعداد نود ها ۴ تا میباشد.
- همیشه می بایست فرمول زیر برای مقدار redundancy صدق کتد
- مقدار redundancy می بایست بیشتر از صفر باشد
- نوع انتقال یا transport پیشفرض این مورد tcp است
- مقدار redundancy اگر وارد نشود به طور اتومات براساس تعداد نود ها محاسبه میشود
redundancy * 2 < #Bricks- Distributed Dispersed
این مدل فایل ها رابین dispersed subvolume هایی پخش میکند و سرعت مدل قبلی را افزایش میدهد.
انتخاب هر یک از موارد بالا کاملا بستگی به محیط شما دارد
نصب و راه اندازی گلاستر استوریج
برای بالا آوردن گلاستر سناریو های مختلفی وجود داره و بسته به این که از چه نوع گلاستر استورجی می خواین استفاده کنین حداقل نود ها می تواند متفاوت باشد. در این مثال ما یک گلاستر استوریج با ۳ نود به صورت mirror یا replicated ایجاد می کنیم در این حالت دیتا در ۳ نود به صورت یکسان ذخیره میشود.
توضیح سناریو :
در این بخش ما نیاز به ۳ سیستم داریم که سعی کنین توزیع لینوکس به روزی داشته باشه من می خوام از دبیان 10 به عنوان سیستم عاملشون استفاده کنم. آدرس هاش به شکل زیر است
192.168.200.51 gluster-node-1 192.168.200.52 gluster-node-2 192.168.200.53 gluster-node-3
مرحله اول – اصلاح DNS
اگر در شبکه سرویس دی ان اس دارین حتما موارد آدرس و نام نود های گلاستر را روی آن اصلاح کنید. اگر هم از این سرویس استفاده نمی کنید بهتر است مقادیر بالا را در فایل etc/hosts/ روی همه ی نود های گلاستر اضافه کنید تا نود ها همدیگر رو با نام ببینند.
نکته : این بخش خیلی مهمه و درصورت عدم رعایت ممکنه جلوتر به خطاهایی برخورد کنین.
مرحله دوم – آپدیت سیستم
همشه بهتر از آپدیت ترین نسخه سیستم عامل در حین راه اندازی اولیه یک سرویس استفاده کنید.
sudo apt update && sudo apt dist-upgrade -yنکته : بهتر است که در شبکه برای تنظیم زمان همه نود ها از سرویس NTP استقاده شود
مرحله سوم – اضافه کردن رپازیتوری گلاستر و نصب پکیج های مورد نیاز
برای اضافه کردن رپازیتوری بسته به سیتم عامل ، ورژن آن و ورژنی گلاستری که می خواین نصب کنین متفاوت است.من چون دارم از دبیان 10 استفاده میکنم ادامه آموزش روی این مورد خواهد بود ولی لینک زیر آموزش اضافه کردن برای توزیع های مختلف را نشان میده که واستون میزارم.
خوب ابتدا کلید gpg را به apt-key اضافه کرده سپس خط مد نظر را سورس لیست اضافه و پکیج ها رو نصب میکنیم.
Add the GPG key to apt: wget -O - https://download.gluster.org/pub/gluster/glusterfs/8/rsa.pub | apt-key add - Add the source (s/amd64/arm64/ as necessary): echo deb [arch=amd64] https://download.gluster.org/pub/gluster/glusterfs/8/LATEST/Debian/buster/amd64/apt buster main > /etc/apt/sources.list.d/gluster.list Update the package list: apt-get update Install: apt-get install glusterfs-server glusterfs-client
مرحله چهارم – پیکربندی دیسک ها
اگر پیاده سازی گلاستر استوریج شما به شکلی هست که به صورت دستی قرار است در ماشین ها مونت شود این قسمتا نیاز به پیکربندی دارد و شما مییایست پیکربندی دیسک و ایجاد volume را داشته باشین. اما به علت اینکه گلاستر اف اس ما برای استفاده خارجی کوبرنتیز هست نیازی به پیکربندی دیسک و ایجاد volume نیست زیرا که سرویس جدایی به نام heketi این کار را به صورت اتوماتیک برای ما انجام میدهد. صرفا نیاز است که مطمین شیم همه نود ها دارای حداقل یک دیسک یا پارتیشن به صورت خام و بدون فورمت است.
نکته: امکان استفاده از LVM نیز وجود دارد که استفاده از اون خیلی پیشنهاد میشه
حال تمامی تود ها در این مثال دارای 1 تا دیسک جدا برای ساخت ولیوم گلاستر هستند.
نکته: تعداد این دیسک ها می تواند بیشتر و حجم آنها متفاپت باشد فقط میزان فضا دیسک خالی هر ماشین با ماشین دیگر برابر است مثلا اینطور نباشه که نود اول دو دیسک 1T داته باشه نود های دیگه یک دیسک 1T. میزان حجم نهایی دیسک ها برای هر نود باید برابر باشه منطقی هم هست چپن قراره به صورت replicated داده روش بریزیم و همه نود ها یک داده رو دارند.
gluster-node-1 sda 8:0 0 20 0 disk ├─sda1 8:1 0 18G 0 part / └─sda2 8:5 0 2G 0 part [SWAP] sdb 11:0 1 1T 0 disk gluster-node-2 sda 8:0 0 20 0 disk ├─sda1 8:1 0 18G 0 part / └─sda2 8:5 0 2G 0 part [SWAP] sdb 11:0 1 1T 0 disk gluster-node-3 sda 8:0 0 20 0 disk ├─sda1 8:1 0 18G 0 part / └─sda2 8:5 0 2G 0 part [SWAP] sdb 11:0 1 1T 0 disk
مرحله چهارم – آشنایی نود ها با یکدیگر
این مراحل نود هارو به trusted storage pool اضافه می کنه و فقط نیازه که روی یک نود انجام شه
ssh gluster-node-1
-->
gluster peer probe gluster-node-1
gluster peer probe gluster-node-2
gluster peer probe gluster-node-3بعد از اجرای دستورات بالا دستور زیر میابست خروجی زیر را داشته باشد و وضعیت همه connected یاشد
gluster pool list
UUID Hostname State
c32aa3ra-7543-4e9c-asdd-2fa7c5177999 gluster-node-1 Connected
3e8fs3b7-0b59-4539-qwee-25852e4hh134 gluster-node-2 Connected
7977fggb-4037-4c1f-ghjj-14b683a77773 gluster-node-3 Connectedحال تمامی نود ها در trusted storage pool قرار گرفتند.
مرحله پنجم – ساخت volume
این مرحله بسته به نوع volume می تونه متفاوت باشه.
دستور کلی آن به شکل زیر است
gluster volume create <NEW-VOLNAME> [stripe <COUNT>] [[replica <COUNT> [arbiter <COUNT>]]|[replica 2 thin-arbiter 1]] [disperse [<COUNT>]] [disperse-data <COUNT>] [redundancy <COUNT>] [transport <tcp|rdma|tcp,rdma>] <NEW-BRICK> <TA-BRICK>... [forceقبل از ایکه بریم سراغ ساخت volume شما می بایست ی دایرکتوری به عنوان brick مشخص کنین. که میتونه یک پارتیشن دیسک یا یک lvm باشه که برای هر سرور به صورت جدا در آن دایرکتوری mount شده و در fstab قرار گرفته است. برای ساخت و اطلاعات بیشتر در مورد lvm مقاله راهاندازی LVM در لینوکس میتونه مفید باشه . (فورمت و نوع این پارتیشن کاملا دست شماست ولی پیشنهاد من استفاده از lvm است چراکه شما می تونین از قابلیت های شگفت انگیز lvm هم بهره مند بشین)
در این مثال lvm در هر سیستم به /data/ در همان سیستم mount شده اسن
ساخت سه نود به صورت replicated
gluster volume create test-volume transport tcp replica 3 gluster-node-1:/data gluster-node-2:/data gluster-node-3:/data force
Creation of test-volume has been successful
Please start the volume to access data.ساخت دو نود به صورت distributed
gluster volume create test-volume transport tcp gluster-node-1:/data gluster-node-2:/data force
Creation of test-volume has been successful
Please start the volume to access data.
ساخت 4 نود نود به صورت distributed replicated
gluster volume create test-volume transport tcp replica 2 gluster-node-1:/data gluster-node-2:/data gluster-node-3:/data gluster-node-4:/data force
Creation of test-volume has been successful
Please start the volume to access data
ساخت 4 نود نود به صورت dispersed
gluster volume create test-volume disperse 4 gluster-node-1:/data gluster-node-2:/data gluster-node-3:/data gluster-node-4:/data
There isn't an optimal redundancy value for this configuration. Do you want to create the volume with redundancy 1 ? (y/n)در مورد بالا مقدار اتوماتیک redundancy را سیستم 1 پیشنهاد داده است با زدن y و اینتر volume ایجاد میشود.
ساخت 6 نود نود به صورت distributed dispersed
gluster volume create test-volume disperse 3 gluster-node-1:/data gluster-node-2:/data gluster-node-3:/data gluster-node-4:/data gluster-node-5:/data gluster-node-6:/data
مرحله ششم – استارت volume
این مرحله باعث استارت و سرویس دهی این volume میشود
gluster volume start test-volume
Starting test-volume has been successfulبا دستورات زیر می توان وضعیت گلاستر را مشاهده کرد
gluster peer status
gluster pool status
gluster volume status [<VOLNAME>]
gluster volume top <VOLNAME> {open|read|write|opendir|readdir|clear} [nfs|brick <brick>] [list-cnt <value>]
gluster volume top <VOLNAME> {read-perf|write-perf} [bs <size> count <count>] [brick <brick>] [list-cnt <value>
gluster volume profile <VOLNAME> start
gluster volume profile <VOLNAME> info
gluster volume profile <VOLNAME> stop
مرحله هفتم – بارگذاری volume در سیستم کلاینت
در سیستم کلاینت می بایست پکیج glustefs-client نصب باشد و با ورژن سرور یکی باشد وگرنه در بعضی موارد باعث مشکلات عجیبی می شود
خوب پس می بایست مراحل 1 ، 2 و 3 بالا را انجام و فقط در مرحله 3 پیکیج glusterfs-server را نصب نکرد
نکته: اجرای مرحله اول در سیستم کلاینت از نون شب هم واجب تره . خیلی جدی بگیرین. من ی روزم سر هیمن مورد رفت 🙂
Update System:
sudo apt update && sudo apt dist-upgrade -y Add the GPG key to apt: wget -O - https://download.gluster.org/pub/gluster/glusterfs/8/rsa.pub | apt-key add - Add the source (s/amd64/arm64/ as necessary): echo deb [arch=amd64] https://download.gluster.org/pub/gluster/glusterfs/8/LATEST/Debian/buster/amd64/apt buster main > /etc/apt/sources.list.d/gluster.list Update the package list: apt-get update Install: apt-get install glusterfs-client fuse attr load Fuse module: modprobe fuse
برای بارگذاری هم میتوان از روش دستی و هم فایل fstab استفاده کرد که به شکل زیر میشود
manual mount command:
mount -t glusterfs -o defaults,_netdev,direct-io-mode=disable,backup-volfile-servers=gluster-node-2 gluster-node-1:/test-volume /mnt/test
fstab file:
gluster-node-1:/test-volume /mnt/test glusterfs defaults,_netdev,direct-io-mode=disable,backup-volfile-servers=gluster-node-2 0 0
خوب تمام شد مرحله پیاده سازی ولی ی سری نکات مربوط به tuning گلاستر هم بهتون میگم تا بتونی کاراییش رو تا حد زیادی بالا ببرین.
اول بحث kernel tunning هست که یکسری پارامترهای کرنل رو سیخ میزنیم و باید روی همه نود های گلاستر انجام شه.
vim /etc/sysctl.d/local.conf
vm.swappiness=0
net.core.rmem_max=67108864
net.core.wmem_max=67108864
net.ipv4.tcp_wmem=33554432
net.ipv4.tcp_rmem=33554432
net.core.netdev_max_backlog=30000
net.ipv4.tcp_congestion_control=htcpخود گلاستر هم واسه خودش پارامتر تا دلت بخواد داره که می تونه خیلی تو روند کاریش تاثیر بزاره.
این لینک برای توضیحات پارامتر های گلاستر خیلی میتونه مفید باشه.
gluster volume set <VOLNAME> <OPT-NAME> <OPT-VALUE>
gluster volume set <volname> performance.cache-size 1GB
gluster volume set <volname> nfs.disable on
gluster volume set <volname> performance.io-cache on
gluster volume set <volname> performance.io-thread-count 16 ## 16 is the default value, possible values 0-65 ##Increasing this should increase performance with increased users as long as the CPU/NIC can keep up.
gluster volume set <volname> performance.write-behind-window-size 1MB
gluster volume set <volname> client.event-threads 3
gluster volume set <volname> server.event-threads 3
gluster volume set <volname> features.cache-invalidation on (default: off)
gluster volume set <volname> features.cache-invalidation-timeout 600 (default: 60)
gluster volume set <volname> performance.stat-prefetch on (default: on)
gluster volume set <volname> performance.cache-invalidation on (default: false)
gluster volume set <volname> performance.md-cache-timeout 600 (default: 1)برای مانیتورینگ گلاستر به کمک زبیکیس این لینک میتونه مفید باشه
همچنین برای ایجاد storageClass از یک گلاستر استوریج در kubernetes می تونین به این لینک مراجعه کنید.
خوب امیدوارم مفید بوده باشه .
یا حق
